
I trust I have managed to reveal one of the undeniably impressive properties of Bayesianism: the more it is attacked, the stronger it gets, and the more interesting the objection, the more interesting the doctrine becomes. This feature, together with the positive successes of Bayesianism and the failures of alternative views, certainly justify giving Bayesianism pride of place among approaches to confirmation and scientific inference.
— John Earman1
WHEN DID THE SUN GO OUT?
As the tale is told, on the very day Jesus was crucified (though the Gospels don't agree on what day or year that was), “the sun was eclipsed” (Luke 23:45) and “there was darkness over the whole world from the sixth hour to the ninth” (Mark 15:33, Matthew 27:45, Luke 23:44). Though one might want to rescue the text by claiming they really meant an ordinary cloud-front just happened to blow in over Jerusalem, that's certainly not what these authors meant. They meant a supernatural darkness covered the whole inhabited world—Luke claimed it was an eclipse of the sun. But a three-hour solar eclipse is scientifically impossible, especially near Passover (as all the Gospels claim it was), which was always celebrated during the full moon—when, rather obviously, the moon is on the other side of the planet from the sun and can hardly get in front of it, much less stay there for three whole hours. A real eclipse lasts only minutes in any one place, as the moon moves pretty fast, and is quite far away. It's also impossible for an eclipse to darken the whole earth—because the moon is so small and so distant, it only barely covers the sun at all, plus the earth spins on its axis at a brisk pace of nearly a thousand miles per hour. So a solar eclipse only darkens a long thin track across the earth, and most of that only partially. You have to be directly under a total eclipse to view it, while partial eclipses don't “darken the land.”
So there can be no doubt; blotting out the sun over the whole known world for three straight hours would be a paranormal event of the highest order. Even arguable scientific explanations (such as a vast dense cloud of space-dust swiftly drifting through the plane of the solar system between the earth and the sun over just those three hours) would require events so astronomically rare that one might argue its coincidence with the death of a man claiming to be the savior of the world would hardly be credible without concluding some superhuman plan was at work. Of course, perhaps it was this very coincidence that caused this claim to be attributed to him rather than someone else, such that had the sun gone out just one week earlier we'd be talking about the Christian Savior James T. Christ, rebel apocalyptic prophet from Joppa (or whoever you care to imagine), simply because he was the one executed at that fortuitous moment. But even then we'd have an astronomical event of the greatest importance that needed our attentive study. This would not be some trivial historical curiosity to file away and forget.
But did it happen at all? It's certainly not likely, since events like that don't just “happen.” If they did, we'd see more of them. If Jesus were struck by lightning on the cross, that would be unlikely, too, since that rarely happens to anyone, but it's still within the realm of the naturally credible, since hundreds of people are un-portentously struck by lightning in any given year, and lifting them up on a stick is practically asking for it. But the sun going out for three hours? When has that ever happened? How likely is it ever to happen? We're talking about some pretty long odds here. If someone came to you today and said the sun had gone out for three hours one odd Friday back in 1983, you'd need some pretty darned solid proof before believing them, precisely because such an event is so unprecedented, while human fibbing is not (much less delusion or error). But suppose you checked and found that, indeed, the event was widely documented in newspapers, scientific reports, video recordings, and the memories and memoirs of countless witnesses the world over, with no witness giving any contrary account. You would rightly conclude that the probability that allof this evidence was the product of a massive worldwide conspiracy (much less a mass delusion on an unbelievable scale) is surely much lower than the event occurring, however rare and whatever its cause.
That would be easily done in this modern day and age. We'd be ideally positioned with access to living witnesses and documentation of every source and kind. But what if the event had occurred in the first century CE? Though by comparison, our access to the evidence would be greatly impaired (the witnesses are all long dead, for example, and newspapers and video cameras didn't exist), it would not be crippled. The entire world at the time had its astronomers—not only hundreds of them throughout the Roman Empire, spanning the whole West from Britain to Syria and from Germany to Africa, but in China, India, Persia, and Babylon as well, and to a lesser extent even among the ancient civilizations of the Americas. They would not fail to document and discuss the phenomenon, some even in scientifically precise detail. The Roman world was also a highly literary age; hardly any member of the elite wasn't writing books or memoirs. And thousands of scraps of original letters and documents survive in parchments, papyri, and other media (mainly from the sands of Roman Egypt), plus thousands of inscriptions and images carved in stone and other materials (across an even wider area). Some astronomical inscriptions also survive from the ancient Americas, as do histories and documents from ancient China, tablets and records from Babylon, and ancient texts from Persia and India. There could not fail to have been mention or discussion of such a remarkable and terrifying event across many of these cultures among their surviving textual traditions and materials (only the farthest would have missed out, being on the other side of the earth at the time). And if indeed that were the case, we would surely have adequate warrant to believe the sun was blotted out for three hours on the corroborated day—for the probability of the entire world, even cultures thousands of miles apart, involving the entire body of ancient scientists and observers, all suffering a simultaneous mass delusion, or conspiring to doctor the record (or any modern deviant attempting this, much less succeeding at it), is surely much lower than the event happening after all.
On the other hand, the universal silence of all these materials, except a single claim in a single religion repeated only in its own documents (and documents relying on those), is extraordinarily improbable—unless the event was entirely made up. Indeed, Christians couldn't even coordinate their own mythology—the Gospel according to John exhibits no awareness of any darkness occurring at Christ's death (see John 19). Only the synoptic Gospels mention it (and they all derive from a single Gospel, Mark), as well as authors using those Gospels. We hear of it nowhere else. So it's more than reasonable to say the sun was not blotted out for three hours. Christians just made that up. And when they did, quite clearly no one was around anymore who cared enough to refute them (or their refutations weren't preserved in the extant record).
The sole alleged exception to this fact even proves the rule. Contrary to the claims of Christian apologists, a lost chronicle of Thallus (in which he supposedly tried to explain this darkness as an ordinary eclipse) can't be dated any more accurately than a century after the fact (so we don't know Thallus wasn't just reading the Gospels and conjecturing a reply), neither can we confirm he ever actually mentioned the event in connection with Jesus (in fact, the evidence suggests he probably didn't), nor that he verified its unusual duration (or even its occurrence). And as far as we can tell, he was neither a witness nor an astronomer, and his text is not only alone, but was not even deemed worth the bother of preserving; hence, actually confirming our conclusion.2 No one else noticed the event, because it didn't happen. We can be quite certain of this, so improbable is the remaining silence in the evidence—or in other words, so strong is our expectation that the evidence would be quite different indeed, had the event really occurred.
This is a slam-dunk Argument from Silence, establishing beyond any reasonable doubt the nonhistoricity of this solar event (for the logic of all arguments from silence, see chapter 4, page 117). This entails, in turn, that the Gospels, even from the very beginning, contain wildly unbelievable claims of inordinately public events that in fact never occurred, yet were never gainsaid by any of the millions of witnesses who would surely have known better. I'll consider the significance of that fact in my next volume. But here, our focus will be on the logic of the argument.
FROM SCIENCE TO HISTORY
Historians need solid and reliable methods. Their arguments must be logically valid, and factually sound. Otherwise, they're just composing fiction or pseudo-history. Much has been written on the method and logic of historical argument.3 And yet, though none of it is aware of the fact, all of it could be reduced to a single conclusion: all valid historical reasoning is described by Bayes's Theorem (or BT). What that is, and why it matters, is the subject of this chapter. That it models all valid historical methods will be demonstrated in the next chapter.
In simple terms, Bayes's Theorem is a logical formula that deals with cases of empirical ambiguity, calculating how confident we can be in any particular conclusion, given what we know at the time. The theorem was discovered in the late eighteenth century and has since been formally proved, mathematically and logically, so we now know its conclusions are always necessarily true—if its premises are true. By “premises” here I mean the probabilities we enter into the equation, which are essentially the premises in a logical argument. Since BT is formally valid and its premises (the probabilities we enter into it) constitute all that we can relevantly say about the likelihood of any historical claim being true, it should follow that all valid historical reasoning is described by Bayes's Theorem (whether historians are aware of this or not). That would mean any historical reasoning that cannot be validly described by Bayes's Theorem is itself invalid (all of which I'll demonstrate in the next chapter). There is no other theorem that can make this claim. But I shall take up the challenge of proving that in the next chapter. If I'm correct, and it is true that BT models what all historians actually do when they think and reason correctly about evidence and explanations, historians would do well to know more about it.
In all empirical sciences, usually the objective is to discover and test different theories against the evidence until we can determine, given all we know, which theory is most likely true. The reason we pursue theories, and not merely gather facts, is that the facts alone tell us little about the world. To infer anything from those facts requires a theory; in particular, a theory of how that evidence came about (and what future evidence might come about in similar conditions). The exact masses, velocities, and accelerations of falling and orbiting objects can be documented, for example, but that's useless information unless we infer from all this data a general pattern—like a universal force of gravitation, its strength and behavior, and what this then predicts about the behavior of projectiles or spaceships, and what it explains about the structure and behavior of the solar system we inhabit. The latter is all theory, however certain we may be that it's true. But not all science is about discovering universal laws or processes or predicting the future. Geology and paleontology, for instance, are largely occupied with determining the past history of life on earth and of the earth itself, just as cosmology is mainly concerned with the past history of the universe as a whole. Yet even then these sciences are making predictions, regarding what ancient evidence might be found in the future, and what ancient events and processes caused the evidence we've already found.4
For example, we can document our testimony to seeing highly compressed rock on a mountaintop with extinct seashells embedded within it. But this information is only useful to us if we can infer from such observations (and others like it) that that rock used to be under the sea and thus has moved from where it once was, and that this rock has been under vast pressures over a great duration after those shells were deposited in it; which are theories of how the evidence came about that, when fleshed out, can predict not only what other discoveries are likely (or unlikely) to be made and where (e.g., other mountains with similar histories will have similar finds waiting for us), but also what's going to happen to regions now beneath the sea millions of years hence. A particular pattern and sequence of layers in a rock formation can even confirm to us specific historical facts, such as exactly when a volcano erupted, a valley flooded, or a meteorite struck the earth thousands of miles away. Such data can tell us where the Mississippi River used to flow millions of years ago (which was not where it is now), how large it then was, its shape, the plants and animals that lived in and around it (many of which no longer do), and much else. All of these conclusions are theories: theories of how all the evidence came about that survives for us to see today. And these theories also entail predictions of what sorts of things will happen to that river over the next few million years. Those predictions will not be exact (they won't tell us exactly where the river will be or what its size or shape will then be or exactly what new plants and animals might inhabit it), but they will be generic (they will tell us what kinds of outcomes are possible or impossible, likely or unlikely, in all these respects).
History is the same. The historian looks at all the evidence that exists now and asks what could have brought that evidence into existence. And tautologically speaking, what most likely brought it about is what most likely happened. She can then infer what other evidence could be found someday (whether finding it is at all likely or not), and what couldn't, if her theory is true. Just as a geologist can predict where the ancient course of the Mississippi River will likely be confirmed to be if further excavation were possible, so a historian can predict what sorts of documentation could someday be found, and if found what we can expect it to contain, if her theories are true—predicting, again, not in exact details, but in that same generic sense, regarding what kinds of evidence should be expected, if any turns up (which is precisely how historians can do any research at all, knowing what to look for, and hope for, in their inquiry). And just as a geologist can make valid predictions about the future of the Mississippi River, so a historian can make valid (but still general) predictions about the future course of history, if the same relevant conditions are repeated (such prediction will be statistical, of course, and thus more akin to prediction in the sciences of meteorology and seismology, but such inexact predictions are still much better than random guessing). Hence, historical explanations of evidence and events are directly equivalent to scientific theories, and as such are testable against the evidence, precisely because they make predictions about that evidence.5
In truth, science is actually subordinate to history, as it relies on historical documents and testimony for most of its conclusions (especially historical records of past experiments, observations, and data). Yet, at the same time, history relies on scientific findings to interpret historical evidence and events. Science and history are thus inseparable. But the logic of their respective methods is also the same. The fact that historical theories rest on far weaker evidence relative to scientific theories, and as a result achieve far lower degrees of certainty, is a difference only in degree, not in kind. Historical theories otherwise operate the same way as scientific theories, inferring predictions from empirical evidence—both actual predictions as well as hypothetical. Because actual predictions (such as that the content of Julius Caesar's Civil War represents Caesar's own personal efforts at political propaganda) and hypothetical predictions (such as that if we discover in the future any lost writings from the age of Julius Caesar, they will confirm or corroborate our predictions about how the content of the Civil War came about) both follow from historical theories. This is disguised by the fact that these are more commonly called ‘explanations.’ But theories are what they are.
Theories in history are of two basic kinds: theories of evidence (e.g., how the content of the Civil War came to exist and survive to the present day), and theories of events (e.g., how that war got started, why Caesar did what he did, why he won, etc.). In other words, historians seek to determine two things: what happened in the past, and why. The more scientifically they do this, the better. And that means the more they attend to the logic of their own arguments, their formal validity and soundness, the better. Historians rarely realize the fact, but all sound history requires answering three difficult questions about any particular theory of evidence or events: (1) If our theory is false, how would we know it? (e.g., what evidence might there then be or should there be?) (2) What's the difference between an accidental agreement of the evidence with our theory, and an agreement produced by our theory actually being true—and how do we tell the two apart? (3) How do we distinguish merely plausible theories from provable ones, or strongly proven theories from weakly proven ones? In other words, when is the evidence clear or abundant enough to warrant believing our theory is actually true, and not just one possibility among many? As in natural science, so in history—I believe Bayes's Theorem is the only valid description of how to correctly answer these questions.6
WHAT IS BAYES'S THEOREM?
The literature on Bayes's Theorem is vast, and usually technical to the point of unintelligibility for historians. But Eliezer Yudkowsky's web tutorial “An Intuitive Explanation of Bayes’ Theorem (Bayes’ Theorem for the Curious and Bewildered: An Excruciatingly Gentle Introduction)” (at http://yudkowsky.net/rational/bayes) provides a good introduction to the theorem, how to use it, and why it's so important. His follow-up article, “A Technical Explanation of Technical Explanation” (at http://yudkowsky.net/rational/technical) is even better, and you will find it very useful in a number of ways, but it requires that you gain familiarity with Bayes's Theorem first. In print, Douglas Hunter, Political-Military Applications of Bayesian Analysis: Methodological Issues, makes an even more palatable introduction. Hunter provides an extended example of how to employ Bayesian reasoning to history, while Yudkowsky's focus is the sciences, but Hunter still covers all the basics and is a good place to start. Likewise, though Hunter was a CIA analyst and writes about using Bayes's Theorem to assess political situations, the similarities with historical problems are strong, and his presentation is intelligible to beginners, using a minimum of actual math. Similarly approaching the kind of problems historians deal with (and thus worth looking at by way of example) are applications of Bayesian reasoning in legal theory.7
Archaeologists are already making serious efforts to employ Bayesian methods, and in quite sophisticated ways. Though their questions and techniques are more advanced than most historians need, the underlying principles, introductory explanations, and governing logic is often still pertinent to historians in all fields.8 Wikipedia also provides an excellent article on Bayes's Theorem (though sometimes less trustworthy in other areas, Wikipedia's content in math and science now tends to surpass even print encyclopedias), although in some respects too advanced for laypeople. But if you do want to advance to more technical issues of the application and importance of Bayes's Theorem, there are several highly commendable texts.9
Formally, the theorem is represented by this rather daunting equation:
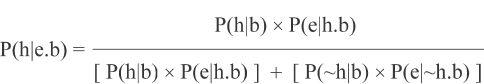
I will explain the specific terms in this equation later.10 For now you only need know that P = probability, h = hypothesis, e = evidence, and b = background knowledge, and all of it roughly translates into English as “given all we know so far,” then:
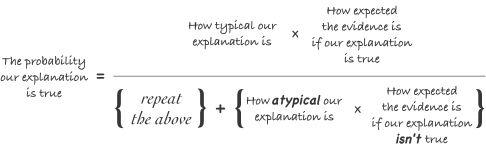
Notice that the bottom expression (the denominator) represents the sum total of all possibilities, and the top expression (the numerator) represents your theory (or whatever theory you are testing the merit of), so we have a standard calculation of odds: your theory in ratio to all theories. The numbers that would go into these terms are probabilities, represented as decimal fractions of 1 (e.g., 25% = 0.25; 80% = 0.80; 100% = 1). Though we don't think in mathematics this way, we are nevertheless doing mathematics intuitively whenever we make any argument for any theory of evidence or events. Every time we say something is “implausible” or “unlikely,” for example, we are covertly making a mathematical statement of probability (and if this is not already obvious, I will prove it in the next chapter, beginning on page 110). The fact that we leave the precise figures vague is no excuse not to attend to what those figures could reasonably be (or reasonably couldn't be). Because what we actually mean when we say things like that has consequences for the logic of any argument we make. Bayes's Theorem simply describes what those consequences are.
The measure of how “typical” our proposed explanation is, is a measure of how often that kind of evidence (or that kind of event) has that kind of explanation (rather than some other). Formally, this is called the prior probability (or just “the prior”). I'll discuss this element more later (here and in chapter 6). For now, it's enough to know that whatever probability we assign to this, the term for how atypical our explanation is must necessarily equal the converse; that is, if our explanation is “the” explanation in 80% of comparable cases, then its prior probability is 0.80, which in turn means the contrary probability (the measure of its “atypicality”) is 1 – 0.80 = 0.20. The fact that a theory's prior probability is not an absolute probability, but a relative probability, is commonly overlooked yet this is one of the most important features of correct reasoning about a claim's probability. In any kind of causal reasoning, the prior does not measure how often such a thing happens, but how often such a thing happening is the explanation of that kind of evidence (rather than something else explaining that same evidence). For example, if someone claims they were struck by lightning five times in their life, the prior probability they are telling the truth is not the probability of being struck by lightning five times, but the probability that someone in general who claims such a thing would be telling the truth. In other words, how often such claims are caused by someone actually being struck by lightning five times, relative to how often such claims are caused by error, delusion, or lies. That's the prior probability that the claim is true in any specific case, in other words how “typically” such claims turn out to be true. When someone claims they've been struck by lightning five times, that twinge of initial skepticism you feel represents your innate estimate of the prior probability that someone who claims something like that might be lying or mistaken. Of course, the rarity of the event plays a role in that calculation. But it's ultimately the frequency with which claims of such rare events are true that is being measured.11 And the converse of this probability (that the claim is true) is the other prior probability (that the claim is, for whatever reason, false).
But the prior probability alone does not tell us whether a claim is true. We must also consider the evidence available in any specific case. That's the role of the two other terms in the equation, which aren't measuring the prior probability of the hypothesis, but the likelihood of the evidence, in other words, how expected that evidence is. The measure of how “expected” the evidence is, is a measure of how likely it is that we would have that evidence (or anything relevantly comparable to it), rather than some other evidence instead, if our theory were true. In other words, if our theory is true, then what sort of evidence do we expect, and how well does the evidence we actually have match that expectation? This is measured by a consequent probability of the evidence (or just “the consequent”).12 In this respect, ‘evidence’ includes not just the actual items of evidence we have, but also the evidence we conspicuously don't have (despite a reasonably diligent search). For example, if missing evidence is unlikely, yet that expected evidence is missing (as in the example of the disappearing sun with which we began), then the consequent probability is low. This is called an Argument from Silence—the validity of which I'll examine in the next chapter (page 117). On the other hand, if the evidence we have is pretty much exactly the sort of evidence we should expect to have, then the consequent probability is high.
The last term in the formula is a similar measure of how expected the evidence is if our theory is false. Unlike prior probability, this is not equal to the converse of the other term, for these two consequent probabilities don't have to sum to one.13 They are measured independently of each other. They can even both equal one. If the evidence is exactly what we should expect regardless of whether the theory we are testing is true or false, then the consequent probabilities are indeed both one, and in such a case we simply don't have any evidence that permits us to tell whether our theory is true or not, apart from its prior probability. For example, if all the evidence we can reasonably expect to have is someone's word, that is exactly the same evidence we would expect to have whether they were lying or telling the truth. Which is why, when we suspect the possibility of lying (i.e., when the prior probability of a lie in that case is not small), we require more evidence than someone's word.
A common mistake is to assume that in estimating this latter consequent probability we are asking how likely the same evidence would be if nothing were present to cause it. To the contrary, we must ask how likely that evidence would be if something else were present to cause it. In other words, how likely is the evidence if some other explanation is true—some explanation other than our own. To answer that question, we have to seriously look for, and seriously consider, alternative explanations of the evidence. When there are many possible explanations, the Bayesian formula can be expanded to account for them all (see page 69), but when only two of those explanations have any significant likelihood of being true, then we can treat our theory being false as equivalent to the alternative theory being true. In such a condition other theories would remain logically possible, but far too improbable to credit, so we can safely ignore them. Because when we ignore such theories, the results we produce using BT will still be a reasonable enough approximation, just not exact to the nth decimal place, which is more than adequate for historians, who have no need of such precision. I'll explain this further in chapter 6 (page 70). For now, you need only accept that wildly implausible theories can be safely ignored when estimating the probabilities of more plausible contenders. And for those, we need estimate only three probabilities: the prior probability a theory is true, the likelihood of the evidence if that theory is true (in other words, the consequent probability on h), and the likelihood of the evidence if some other theory is true (the consequent probability on ~h).
When we have reasonable values for all these terms, Bayes's Theorem entails a particular conclusion as to how probable our theory is—given all that we know at that point in time, since a Bayesian result is a conditional probability. It's conditional on current knowledge, which means if we discover new theories or facts, the conclusion might change. Bayes's Theorem thus tells us what we are warranted in believing at any given time, fully acknowledging that this can change with new information. If, for example, Bayes's Theorem tells us our theory has a final posterior probability of 80%, then given what we now know there is an 80% chance we're right—but that means there is also a 20% chance we're wrong. Since there will always be some probability our theory is false (however small that probability may be), this accounts for the possibility that new information could reveal we were wrong all along. But a high probability also entails that such a reversal is unlikely, which is why we are warranted in trusting it. You would say it's then a good epistemic bet.
A BAYESIAN ANALYSIS OF THE DISAPPEARING SUN
Applying all this to the historical claim of a global darkness with which we began this chapter, we can see how the argument presented there in common colloquial terms actually corresponds to the structure of Bayes's Theorem. The theory to be tested (h) is that the sun actually went dark for three hours in the early first century (in other words, that the claim being made is true). The alternative theory (~h) is that this didn't happen—in other words, that the accounts we have of it were fabricated by storytellers (regardless of who or why or how). The evidence (e) consists of the claims in the Gospels (and sources citing them) and the vast and peculiar absence of other evidence outside the Gospels (and sources citing them). Our background knowledge (b), which includes everything we know about science, astronomy, human nature, the society and culture of the first century, and so on, tells us that claims like “the sun was blotted out for three whole hours” (especially when even an ordinary solar eclipse would have been impossible) are almost always caused by someone telling tall tales, and rarely caused by such remarkably rare events actually happening. In other words, countless other cases establish that fibbing or delusion is far more commonly the cause of such tales than actual unprecedented phenomena—the more so in “sacred tales,” such as the Gospels.
Though “rarely” certainly doesn't mean “never,” the conclusion still follows that the prior probability of h (“the story was told because it was true”) is very low, while the prior probability of ~h (“the story was told because it was made up”) is very high, because that's how it usually turns out in such cases. This is, in fact, what we already assume when we are immediately skeptical of wild claims like that (this is sometimes amusingly called the ‘Smell Test,’ the logic of which I'll examine in the next chapter, page 114). When someone once told me they had seen a demon levitate a girl over her bed for half an hour, I already knew it was very unlikely this story would turn out to be true. That's my intuitive recognition that the prior probability of hallucinating or making that stuff up is far higher than the prior probability of such a claim actually being true. This is because human fibbing, illusion, hallucination, or delusion is far more common, and because such fabulous displays of demonic telekinesis have never been reliably documented, and thus even if they happen, they happen far less often than all those other causes of the same kinds of claims.
Still, the odds aren't zero. There are certainly conceivable (albeit extremely rare) natural explanations of a bizarre solar darkness, so even if I rejected the supernatural outright, I would still have to admit there is some small probability that this darkness really happened. And I can't honestly reject the supernatural outright anyway. For there is always some small probability I'm wrong about there being no supernatural causes or phenomena—even if the odds of my being wrong about that are even lower than the odds of a natural cause of a three-hour blockage of the sun.14
But that doesn't conclude the matter. Even claims with a very low prior probability can still turn out to be true—and not only true, but supremely credible—because the consequent probabilities can still diverge enough to overcome even the smallest prior. In other words, when the evidence really is good enough, even the incredibly improbable becomes likely. I can certainly imagine sufficient technical and professional documentation of demon levitations that would convince me demon levitation was real. So could directly witnessing it myself. Indeed, if everything that happened in the movie Constantine had actually happened to me, it would be irrational not to believe. Such bodies of evidence being fabricated or mistaken (or even hallucinated) would be far less probable than the event simply being true (provided we could confirm, to a high probability, the absence of any likely explanation like drugs or schizophrenia). But a half-hour demon levitation that somehow no one thought even to record on video (despite this being the twenty-first century when even common cell phones can record video) is contrary to reasonable expectation. The absence of evidence here is suspicious, and therefore actually less probable if the story is true than if it's false (since the lack of such obvious documentation is always expected for a lie, but not as expected for the real deal).
This would not have been the case twenty years ago, when recording video was expensive and few had the resources for it, such that we would not expect video to be made. But now video cameras are everywhere and cost nothing to operate. It would be unusual for someone to know they are observing an incredible event and for a whole half hour not make any effort to record it. It would be many times more unusual if no one ever did this when demon levitations are supposed to be frequently occurring all over the world every year. And unusual means infrequent, which means improbable. But a liar will always have an excuse for why they didn't do something so obvious. That would not be unusual at all. The difference may be small (perhaps making for a weak Argument from Silence, as I discuss on page 119), but it's still a difference, and it doesn't favor the claim being true. This still doesn't entail that lack of documentation makes the claim unlikely. For there can be honest excuses, too. So it merely lowers the probability. How much lower will depend on particulars, and the priors. But when the prior is low, even honest excuses cannot make a claim likely. That's precisely why “anecdotal evidence” is worthless in science, and in courts of law. It's not that anecdotal evidence is necessarily false. It's just that it's much too likely to be false. Conversely, the more extensive and reliable the documentation we have, the more a low prior can be overcome. Because the odds of error or fabrication then decline.
Applied to the darkness scenario, the example I gave of a claimed three-hour worldwide darkness in 1983, which we confirmed in all the ways we should expect, demonstrates the same principle: such a scale of evidence is so improbable as a fabrication (or as anything else other than the event actually happening), that even though the story being true has an extremely low prior probability, the evidence in this case would more than overcome it (being even more improbable unless the story were true, entailing sufficiently divergent consequent probabilities). In contrast, the vast absence of the evidence we should expect from the world's cultures of the first century is vastly improbable if that story is true, yet entirely expected if it's false. Therefore that claim should not be believed. This kind of demarcation between evidence and background information is characteristic of historical method, in which e consists of the evidence to be explained by h (and by its competitors, represented by ~h), and b consists of what has typically happened before, in other relevant cases. Typically suns don't go out for three hours in the middle of the day. That is what we derive from our background knowledge. And that gives us our prior probabilities. The evidence in this particular case is then the status of documentation that the event (or its fabrication) is expected to cause. In other words, how typically do we get that kind of evidence, given that cause (h or ~h). And that gives us our consequent probabilities. The equation does the rest.
Representing these two options mathematically, Bayes's Theorem models this very line of argument as follows. I'll start with the hypothetical darkness in 1983. Merely for convenience I will employ the value 0.01 (or 1%) for the prior probability that such a story would be caused by a real unprecedented darkness rather than by being made up. Again, this is not the probability of such an unprecedented darkness occurring, but the probability that having a story of such a thing would indicate it did. In other words, it's whatever we find to be the typical probability that anyone who told such a story would be telling the truth. I will also use 0.00001 (one in a hundred thousand) for the consequent probability that vast worldwide evidence confirming the event would exist even if the story were made up (which is really far less likely than one in a hundred thousand). The result would be identical with even vastly smaller numbers than these (like 10-9 and 10-12, respectively), since it's their ratio that determines the outcome rather than their actual values—and if anything their ratio would be greater, not smaller, which would confirm my point a fortiori (a method I will discuss on page 85). Don't worry too much about the exact details of all the math here. I'll discuss it later. For now just follow along:
|
h1983 |
= |
such a darkness happened in 1983 |
|
~h1983 |
= |
the darkness of 1983 is a made-up story |
|
e1983 |
= |
all the expected documentation is found confirming the darkness in 1983 |
|
b |
= |
everything we know about human nature, astrophysics, technology, the culture and society of 1983, etc. |

|
= |
0.9990 (rounded) = 99.9% = the probability that this darkness claim (h1983) is true, given all the evidence we have and all our current background knowledge. |
So even if there was only a 1% chance such a claim would turn out to be true, that is, a prior probability of merely 0.01, the evidence in this case (e1983) would entail a final probability of at least 99.9% that this particular claim is nevertheless true. The prior probability may even be one in a billion, but the consequent probability of the evidence (of e1983) would also more realistically be at least one in a trillion (i.e., still a thousand times less likely), which would produce exactly the same result: a 99.9% chance the claim is true (since the ratio is the same). Thus, even extremely low prior probabilities can be overcome with adequate evidence.
Practically the same result would be obtained for the Gospel claim of a world darkness if we had the evidence we would then expect (vast multicultural attestation). But we don't. Bayes's Theorem models the ensuing argument again, and this time I'm favoring the theory with even more generous numbers:
|
h30s |
= |
such a darkness happened in the 30s CE |
|
~h30s |
= |
that darkness is a made-up story (deliberately or by hallucination, etc.) |
|
e30s |
= |
a collection of interrelated hagiographies composed decades later (i.e., the Gospels) contains the claim (as well as texts using them), but no other documents independently confirm it |
|
b |
= |
everything we know about human nature, astrophysics, technology, ancient sacred writings in general, the New Testament documents in particular, early Christianity, the culture and society of Palestine and the Roman Empire in the first century, etc. |

|
= |
0.000101 = 0.01% (rounded) = the probability that this darkness claim (h30s) is true, given all the evidence we have and all our current background knowledge. |
Here we find the claim is almost certainly false (with odds of around one in ten thousand, and that's at best), because the evidence we have is not at all expected on the theory that this three-hour darkness actually happened. Indeed, the odds that we would have such a universal silence of other witnesses is far lower than the one percent I assigned it here. Yet lowering that number reduces the odds of the claim being true even further (and as for the previous example, all the same goes for the prior probabilities, too). In contrast, the evidence we have is exactly what we should expect if the story was made up: only three hagiographies, two of them directly derived from the first, and texts relying on these, repeating a mythical claim about a divine hero. Hence, I assigned this evidence a probability of 100 percent (or as near to it as makes no relevant difference mathematically—a distinction I'll say more about in a moment)—because if the story were made up, that's exactly the kind of evidence we'd have.
The point of these examples is to illustrate that how we normally reason about claims like this is exactly described by Bayes's Theorem, even if we never knew that. Bayes's Theorem is thus not an alien way of thinking. It's just an exact model of how we always think (when we think correctly). Thus, when applied correctly, BT will not only represent correct thinking about any empirical claim; it will help us identify and expose incorrect thinking. Because the one thing Bayes's Theorem adds to the mix is an exposure of all our assumptions and how our inferences derive from them. Instead of letting us get away with using vague verbiage about how likely or unlikely things are, Bayes's Theorem forces us to identify exactly what we mean. It thus forces us to confront whether our reasoning is even sound.
WHY BAYES'S THEOREM?
The two main advantages of the Bayesian method are that no one can deny the conclusion who accepts the premises (provided those premises are validly stated within the requirements of the theorem), and it forces us to consider what those premises really ought to be (which is to say, what probabilities we ought to put into the equation), thus pinning down our subjective assumptions and making them explicit and thus accessible to criticism (even by ourselves). Understanding the logical structure of a sound Bayesian argument, as formally represented in BT, can thus prevent historians from making specious or fallacious arguments, or from being seduced by them.
With BT, instead of myopically working out how we can explain all the evidence “with our theory,” we start instead by asking how antecedently likely our theory even is, and then we ask how probable all the evidence is on our theory (both the evidence we have, and the evidence we don't) andhow probable all that evidence would be on some other theory (every other theory that has any claim to plausibility, but especially the most plausible alternative). Only then can we work out whether our theory is actually the best one. If we instead just look to see if our theory fits the evidence, we will end up believing any theory we can make fit. And since that will inevitably include dozens of theories that aren't actually true, “seeing what fits” is a recipe for failure. In fact, this is worse than failure, since we will have deceived ourselves into thinking the method worked and our results are correct, because “see how well the evidence fits!” That's the result of failing to take alternative theories of the evidence seriously. That this is exactly what has happened in Jesus studies (as shown in chapter 1) should be proof enough that historians need a new method. One that actually works. And as far as I can see, BT is the only viable contender.
This is all the more important because psychologists have found that this ‘see what fits’ approach is a slave to confirmation bias (where we only see or remember data confirming our hypothesis, and overlook or forget data disconfirming it), which is a fallacious mode of reasoning biologically innate to the human brain (Wikipedia maintains an excellent and well-referenced article on it). Yet it is diametrically opposite the scientific method,15 which instead tests theories by looking for evidence against them (and confirmation then comes only from not finding it), which requires an investigator to imagine what evidence should exist if his theory is false.16 And that requires taking seriously alternative explanations of what a theory is meant to explain. Historians need to do the same.
The applicability of BT to all historical arguments and hypotheses will be proved in the next two chapters. Here I shall only outline the underlying principles and logic that warrant learning and applying BT, and then I'll meet the most common objections to the idea of applying it to history. Why should historians use it? That's the question I'll answer here. Following that, I will address the formal mechanics of BT, and then meet several more technical objections to the idea of applying it to history that then arise.
The first fundamental observation that should open anyone's mind to learning and applying BT is the principle of nonzero probabilities. As discussed in chapter 2, there are two different kinds of probabilities: physical and epistemic. As argued there, the fourth axiom holds: all empirical claims about history, no matter how certain, have a nonzero probability of being false, and no matter how absurd, have a nonzero probability of being true. The only exceptions I noted are claims about our direct uninterpreted experience (which are not historical facts) and the logically necessary and the logically impossible (which are not empirical facts).17 Everything else has some epistemic probability of being true or false. Once we accept this, Bayes's Theorem applies. Methodologically, for every observed fact, some explanation can be devised to explain it away in support of anyconceivable claim or theory. So you cannot end any debate by declaring that you “can” explain a piece of evidence. Per my fifth axiom (in chapter 2) just because a theory can explain a fact doesn't mean that theory is the explanation of that fact. The question must be which explanation, among all the viable alternatives, is actually the most likely. And that's where Bayesian reasoning enters in. If all explanations have some probability of being true, the comparison of their probabilities must entail that one of them is more probable than the others—or that none is, in which case we can'tsay which theory is correct. Either way, BT is the only means of sorting this out.
“But what has math to do with history?” The most common objection to this is that BT involves math, and we don't think in math. Historians certainly don't do math. What has mathematics to do with historical reasoning? Bringing numbers into it seems suspect. But that's naive. The reality is that we do think in math. All the time. And historians most of all. We just don't know we're doing it. Every time you accept or reject a conclusion because something is “unlikely” or “credible” or “implausible” or “more likely” or “most likely,” you are doing math. You're just using ordinary words instead of numbers. Select any claim in the world, and you will immediately be able to say roughly how likely you think it is—in some verbally descriptive way (“very probable,” “extremely improbable,” “somewhat likely,” “as likely as not,” etc.). You will even be able to rank many claims in order of their likelihood. And when presented with a new claim, you'll be able to insert it somewhere into that order again where you think it goes. And you do this all the time whenever you sift through competing theories of evidence and events. All of this entails mathematical thinking. Because as soon as you say x is more than y, you are doing math.
In fact, your thinking is even more mathematically precise than that. When you say something is “probably true,” you mean it has an epistemic probability greater than 50%. Because that's what that sentence literally means. And when you say something is probably false, you mean it has a probability less than 50%. And when you say you don't have any idea whether a claim is probably true or probably false, you mean it has a probability of 50%, because, again, that's what that sentence literally means. Likewise, when you say something is “very probably true,” you certainly don't mean it has a probability of 51%. Or even 60%. You surely mean better than 67%, since anything that has a 1 in 3 chance of being false is not what you would ever consider “very probably true.” And if you say something is “almost certainly true,” you don't mean 67% or even 90%, but surely at least 99%.
And when you start comparing claims in order of likelihood, you're again thinking numbers. That the earth will continue spinning this summer is vastly more probable than that a local cop will catch a murderer this summer, which is in turn more probable than that it will rain in Los Angeles this summer, which is in turn more probable than that you'll suffer an injury requiring a trip to the hospital this summer. And so on. You certainly don't know what any of these probabilities are. And yet you have some idea of what they are, enough to rank them in just this way, and not merely rank them, but also rank them against known probabilities, because you know there is data on the frequency with which people like you get hospitalized for injuries, the frequency with which it rains in L.A., the frequency with which murderers are caught in your county, even the frequency with which the earth keeps spinning every year (we have data on that extending billions of years back, not just for the earth itself, but for all the phenomena that could stop the earth spinning). Thus even a merely ordinal ranking of likelihoods always translates into some range of probabilities. In fact, because you know each is more likely than the next, and roughly how much more likely, probability ratios are implicit in your ordinal ranking, and as it happens BT can proceed with just these ratios, without ever knowing any of the actual probabilities (as I show on page 284). And yet you will still often know in what ballpark each probability actually lies, because you can often relate them to a well-quantified benchmark, something whose probability you actually know. And when you think about it, you'll agree this knowledge is not completely arbitrary, but entirely reasonable and founded on evidence (such as your own past experience and study of the relevant facts and phenomena). You might never have thought about any of this, but your being unaware of it doesn't make it any less true.
Math is in your brain. It's a routine component of your thinking about anything and everything. BT just compels you to be honest about it and take seriously what that means. But mathematics itself is a difficult and foreign language. Most people are simultaneously bored and terrified by it.18 So I will use numbers and formulas sparingly and simplify everything as far as I possibly can. In historical reasoning, this works well enough because we never have and thus don't need the advanced precision scientists can achieve (and indeed, many applications of BT can become exceedingly complex, especially in the sciences).19 But that doesn't change the fact that the logic you always use when evaluating claims is inherently mathematical. Historians, by dealing with claims that very often can only be known to varying degrees of uncertainty, rely even more routinely on mathematical reasoning than the rest of us. That's why it's especially perverse for them to refuse to admit this or examine the actual logic of it.
When we introspectively examine how we intuitively estimate probabilities, we discover that we rarely think in absolutes. We all arrange our knowledge in cascades of different levels of confidence; some things we believe are more probable than others, and almost nothing we can say is absolutely 100% certain. Thus we already quantify our beliefs, even when we don't think exactly how or describe what we're doing using actual numbers. And again, this is especially true in history, where the data is often scarce and problematic, and thus our beliefs are often far less secure than when confronting the results of science or journalism or direct personal experience. So we shouldn't hide from these facts. BT simply describes, or ‘models,’ ideal reasoning about empirical probabilities. Like any logical syllogism, if you believe the premises, you must necessarily believe the conclusion, because the conclusion follows from those premises with deductive certainty. And those premises are the relative priors and the relative consequents: how much more likely (how much more typical) is one hypothesis than another on prior information, and how much more likely (how much more expected) is the evidence on one hypothesis than on another. And whether we're correct or not, or aware of it or not, we always have beliefs about what those relative probabilities are (as I'll prove in chapter 4; if you want to look at that now, jump to page 110).
This means if you don't follow BT, even intuitively, then you are not behaving rationally. You will be entertaining contradictory beliefs. And since BT describes the best way to reason, you will always reason better, and thus your beliefs will be more secure, when you follow BT, than when you just do the same thing intuitively, not really sure why your hunches are as they are or why your convictions should really follow from them. BT helps with this by exposing the numerical assumptions you are already making, and revealing their correct logical relations. And like any logical argument, since the conclusion (the final probability determined by BT) necessarily follows if the premises are true (the two priors and the two consequents), if your beliefs about what those premises are, are well-established or defensible, so is the conclusion.
“But math is hard.” Another objection is that when using BT it's easy to screw up. There are many ways to err in Bayesian analysis—including numerous common fallacies in reasoning about probability.20 Thus, to use BT competently it's important to get familiar with probability theory and the mathematics of probability and how not to err in applying it. But you won't avoid all those errors by avoiding BT. You will continue to make many of the exact same errors, only without being aware of it, whereas working with BT will force you to confront the possibility of these errors and so compel you to learn how to avoid them. Some errors, though, will be unique to using the language of mathematics. For example, all hypotheses you compare using BT must be incompatible (so that P(h|~h) = 0), and you have to attend to the correct means of differently treating independent and dependent probabilities. And so on. This is all statistics 101 and will be learned from any introductory college course or text. More advanced statistical techniques won't normally be of use to historians, so you needn't worry about them. But most errors are already commonplace even among those who have never heard of BT, such as developing overconfident priors or misestimating the likelihood of an alternative theory generating the same evidence. BT will actually help you catch these errors by exposing all the consequences of making them, and by forcing you to validly ascertain those probabilities instead—instead of pretending your reasoning isn't already relying on them (and often uncritically). Hence, avoiding BT will actually make your reasoning more susceptible to error. And in the end, “it's too hard” is not an argument we should ever hear from a professional historian—because mastering difficult methods is what separates professionals from amateurs. The bottom line is, if you're a historian, learning probability theory is your job.
“But history isn't that precise.” A third worry is that math implies precision, yet in historical argument there can't be anything so precise, so using mathematical methods will give the false impression of precision where there is none. After all, you might feel justified saying something is “very probable,” but that doesn't mean you know its probability is, say, exactly 83.7%. But the mistake being made here is assuming the one entails the other. You don't have to claim to know the exact probabilities in order to use BT. I'll discuss the mechanics of how to use inexact math in the next section.21 For the purpose of BT is not to coax you into asserting precision you can't justify, but to correctly represent the logical consequences of the ranges of probability you can justify. Any uncertainty can be represented mathematically. And that uncertainty will validly carry over from the premises to the conclusion. In fact, that's the very merit of BT: it correctly carries over all the uncertainties of your premises into your conclusion. BT can still be abused and misused or used incompetently or incorrectly. But identifying examples or possibilities of such abuse is not an argument against using BT, but against using it incorrectly.
It also isn't necessary that all historical writing and argument be mathematically formalized. It's only necessary that however historical claims are written and argued they be capable of transformation into a mathematical formalism—because that formalism represents the actual logic of any informally stated argument. The first section of this chapter, on the historicity of the sun going out for three hours, shows how a Bayesian argument can be articulated in plain English without any equations, numbers, or math. But to be checked and confirmed, it must be capable of being modeled by Bayes's Theorem, as was accomplished in a later section of this chapter. And when it is thus modeled, the conclusion must prove the same. Otherwise, the “plain English” will only have disguised a logically invalid or unsound argument. BT is thus a means of checking our work. We won't always have to show our work. But we should always be capable of doing that work, and doing it competently and correctly. And sometimes we will need to show our work, precisely so it can be checked and debated.
MECHANICS OF BAYES'S THEOREM
The following shall be the most math-challenging section of the book. It is essential to understand the math, because the math represents a logic, and this logic models the structure of all sound historical reasoning in every field of human knowledge (which I'll prove in the next chapter). The complete BT equation is again:
Here ‘P’ stands for ‘epistemic probability,’ and the symbol ‘|’ represents conditional probability, for example, P(x|y) means the probability of x given y (i.e., what the probability of x is if we assume y is true). For example, the probability that a given person is named John given that that person is a girl is far lower than the probability that just anyone is named John. The former is a conditional probability. The variable h stands for ‘hypothesis’ (an explanation of the evidence we intend to test); e for ‘evidence’ (the evidence we intend to explain with h); b for ‘background knowledge’ (everything else we know); and ~h stands for all other hypotheses alternative to our own (all other possible explanations of the same evidence).
P(h|e.b) thus means “the probability that our hypothesis is true, given the evidence and all our background knowledge” (in other words, “the probability that our hypothesis is true given everything we currently know”), and this probability follows necessarily from four others: P(h|b), which means “the probability that our hypothesis would be true given only our background knowledge”; P(~h|b), which means “the probability that our hypothesis would be false given only our background knowledge”; P(e|h.b), which means “the probability that we would have all the evidence we actually do have, given all our background knowledge, if our hypothesis were indeed true”; and, finally, P(e|~h.b), which means “the probability that we would have all the evidence we actually have, given all our background knowledge, if our hypothesis were instead false.” From those four probabilities, the conclusion necessarily follows, which is the posterior probability, which in turn is simply the epistemic probability that our hypothesis is true.
If that “epistemic probability” is greater than 0.50 (i.e., 50%), then we have sufficient reason to believe our hypothesis (h) is more likely true than not, although our certainty will be attenuated to the actual value of that probability. So an epistemic probability of 0.90 leaves us far more certain that h is true than an epistemic probability of only 0.60, which would leave us very uncertain, leaning only slightly in favor of h being true, harboring considerable doubt. To calculate the epistemic probability for any h, we need to estimate only three values (from which the fourth automatically follows).
Each of these values is the equivalent of a ‘premise’ in a logical argument. Just as in any other logical syllogism, the conclusion (in this case, the epistemic probability we end up with) is never more certain than the weakest premise. Therefore, to apply BT correctly we often must allow for considerable degrees of error and uncertainty when assigning values to these three variables. Those variables are the prior probability your hypothesis is true (which is P(h|b)), the consequent probability of the evidence on your hypothesis (which is P(e|h.b)), and the consequent probabilityof the evidence on any other hypothesis (which is P(e|~h.b)). And from the first of these follows a fourth: the prior probability of any other hypothesis being true (or P(~h|b), which always equals 1 – P(h|b)). You can substitute for the last two of these premises the single premise P(e|b), as shown in the appendix (page 283), but that becomes less intuitive and more difficult for nonmathematicians to use correctly. You can also do the math in the form of “odds” instead of “probabilities” (page 284), but that often requires converting one to the other, an unnecessary step.
Sometimes you will want to take into account numerous hypotheses distinctly. For example, there may be two hypotheses competing against your own, one of which has a high prior probability but a low consequent probability, while the other has a high consequent but a low prior. Treating them together as a single competing hypothesis (~h) would thus be difficult to represent accurately, requiring you to tease out both and treat them separately. If you want to distinguish several competing hypotheses like this, you simply expand the equation, like this:
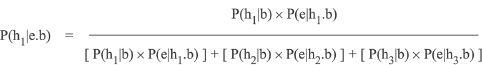
If you want to test more than two alternatives to your own, just add as many boxes to the denominator as you need (e.g., “…+ [P(h4|b) × P(e|h4.b)] + [P(h5|b) × P(e|h5.b)]…” etc.). Just remember that all the prior probabilities in any expanded equation must still sum to 1. For example, if testing five hypotheses altogether (yours against four others), then you must ensure that P(h1|b) + P(h2|b) + P(h3|b) + P(h4|b) + P(h5|b) = 1.
The mechanics of prior probability
The fact that all priors must sum to one is a useful aid to estimating priors. First you exclude all hypotheses with vanishingly small priors. For example, “space aliens did it” is always so inherently improbable its prior will surely be far, far less than even one in one hundred, indeed more on the order of one in a billion (or 0.000000001) or even less. So if there is no compelling evidence for that hypothesis at all, its effect on the equation will be essentially invisible. You can ignore it. Even the sum of the priors for every conceivable harebrained hypothesis will be substantially less than that. So unless there is specific evidence on hand for any of them, we can ignore them all.22 That will result in your equation only producing an approximation of the probability that a given hypothesis is true, but that is all you need in historical analysis. We don't need precision to the tenth decimal place when the odds of an unlikely hypothesis being true are going to be a thousand or million times less than any more plausible hypothesis. So historians can simplify their labor by treating absurdly low probabilities as 0 percent and absurdly high probabilities as 100 percent (until they have reason not to—I'll say more about all this in chapter 6, page 249). That leaves you to deal only with the hypotheses that have more credibility.
If there is only one viable hypothesis, all others being crazy alternatives, then the sum of all the latter can become the prior probability of ~h as a catch-all alternative, and a very low probability it will be. But usually there are at least two or three viable hypotheses (or even more) vying for confirmation. Then it's only a matter of deciding what their relative likelihoods are, based on past comparable cases. How often are stories of miraculously darkened suns made up, relative to how often suns actually get blotted out? Even if you don't have other stories of the sun going out, you have comparable cases, such as tales of the moon splitting in two, armies marching in the sky, and crucifixes and Buddhas towering over the clouds. Adding it all up, you get a reference class (a procedure I'll discuss more in chapter 6), in which we find most of the comparable cases are ‘made up’ (or hallucinated or whatever else) rather than ‘actually happened’ (unless we agree that most of those cases are real, but then we must face the consequences of our now believing that giant space Buddhas visit earth and mysterious cloud armies might descend upon us at any moment). “Most” is a numerical assertion, especially in this context, where you certainly don't mean six out of ten such events are real and the other four made up. You will probably be quite confident that no more than one in one hundred or even one in a million of them could have been real. If you settle on the former, you have a prior probability that any such story is real equal to 0.01 and therefore a prior probability that any such story was made up (or merely records an illusion, delusion, or hallucination) equal to 0.99 (because these two options exhaust all possibilities, so we know the odds that one of these possibilities is true is 100%, and 100% – 1% = 99%).
I'll explain later why you might settle on that specific number. For now the point to be made is that priors must be assessed by comparing all the viable hypotheses against each other and deciding how likely each is relative to all the others—not in isolation from them. The biggest mistake amateurs make in determining priors in BT is to mistake the probability of an event happening with the prior probability of a story about that event being true. The physical probability that a giant Buddha will materialize in the sky is certainly astronomically low. But that's not the same thing as the epistemic probability that, when someone claims to have seen a giant Buddha materialize in the sky, they are neither lying nor in error. The priors in BT represent the latter probability, not the former. For only then will the prior probability of ‘actually happened’ and the prior probability of ‘made up’ (or whatever else) add up to exactly 100%, as they must do for any argument to remain logically valid.
The mechanics of consequent probability
Once you have your priors, you have to estimate the consequents. P(e|h.b) represents how likely it is that all the specific evidence we have (everything included in e) would exist if our hypothesis (h) is true. In historical reasoning, this means the specific evidence that h (and its competitors) is meant to explain or has to explain. So if there is anything in e that we would not expect on h, then the consequent probability will be less than 1, in exact proportion to how unexpected the contents of e happen to be. Conversely, P(e|~h.b) represents how likely it is that all the specific evidence we have would exist if our hypothesis is false. But if h is false, then necessarily something else caused the evidence in e, and therefore some other hypothesis must be true. So we have to ask ourselves what the most likely alternative explanation actually is (or explanations, if several are plausible). Only then can we estimate how likely it is that the alternative(s) would generate the evidence we have.
These two probabilities don't have to sum to one. They can even be the same probability. They can even both be one. For if two hypotheses, h1 and h2, perfectly explain all the evidence—if all that same evidence would always exist on either hypothesis—then the consequents for both are indeed one (i.e., 100 percent). In such a case, there happens to be no evidence available that can tell the difference between them. So all we have to go on is what was typical in past cases, in which event the priors alone will tell us what's most likely. If, for example, a bunch of Tibetan peasants report seeing a giant Buddha in the sky and there is no way to test that claim against any other evidence, we have to conclude they either hallucinated en masse or fabricated the story (or are delusional or victims of an optical illusion, etc.), not because the evidence of the case verifies this conclusion (we would have exactly that same evidence—their mere report—whether the story was true or false), but rather because that's the most inherently probable explanation. That's why extraordinary claims require extraordinary evidence: to overcome the overwhelming prior probability against such claims being true.23
Estimating consequents is simply a question of asking yourself some questions about what each plausible hypothesis actually predicts. Begin by asking yourself if the evidence would be any different if your hypothesis were false. Then ask how different it would be and assign that a value in terms of likelihood. If the evidence wouldn't be any different at all, then the alternative consequent, (P(e|~h.b)), equals one. If, on the other hand, the evidence would certainly be very different, then the alternative consequent must necessarily be far less than one. For example, consider our hypothesis that the darkened sun story was made up (or merely records the hallucination of a few fanatics): if that hypothesis were false, then the sun really did go out, in which case the evidence would be vastly different indeed (we would have nearly worldwide attestation in countless sources). The alternative consequent would therefore have to be very low (I assigned it a value of one in one hundred, and that was being absurdly generous).
Next, ask yourself if the evidence could actually be better. Could your hypothesis be even more confirmed than it already is? Such evidence, if you had it, would lower the alternative consequent even more. Accordingly, the absence of such evidence must be reflected in allowing the alternative hypothesis a higher consequent probability than you might otherwise have assigned. It may seem counterintuitive, but the best way to increase the probability of your theory being true is to decrease the probability of the evidence on every other viable theory. That's the actual effect of finding and presenting more evidence: such evidence makes alternative explanations less likely, hence making your explanation more likely. If even a single item of evidence is much less likely on any theory but yours, then that's what it means to call that item “very good evidence.” The harder it is for alternative theories to explain that evidence, the stronger the support it gives to your theory. Likewise, probabilities accumulate; hence, the more evidence you have, if each item individually is less likely on alternative theories, then having all of that evidence is much less likely. It may be unlikely to have one eyewitness attesting the darkening of the sun, for example, but to have ten independent eyewitnesses doing so would be ten times less likely—not in a strictly literal sense (the actual math would vary from case to case) but it would involve ten acts of multiplication, each of which reducing the probability further. Thus both the quality and quantity of evidence are accounted for in BT.
Then turn the tables. Ask yourself whether there is any evidence that is what an alternative hypothesis would predict, but that your hypothesis doesn't, or at least not as well. If there is, then your consequent (P(e|h.b)) must be reduced to reflect how unlikely that coincidence would be if your hypothesis were still true. If there is a forged letter among your evidence, and your theory doesn't explain why it's there, but a competing theory does, and if both theories explain all the remaining evidence equally well, then your consequent must be less than the other consequent, which means your consequent cannot possibly be one, so it must be lowered to reflect the fact that the evidence you actually have is at least somewhat unexpected. And the other consequent must then be higher, as much higher as reflects how much more likely the evidence is on that alternative explanation.
This can get complicated, because reality is often not so black and white. For example, if you hypothesize that your neighbor is trustworthy but you discover he has a criminal record, that is not something your hypothesis would predict, but it is something the alternative hypothesis (that your neighbor isn't trustworthy) would predict (predict, that is, as having at least a higher than average probability, which is why, if you found him untrustworthy and then discovered he had a criminal record, you wouldn't be surprised). And yet, that alternative theory does not entail your neighbor will have a criminal record (he can still be untrustworthy without having a criminal record). His having such a record is just more likely on that theory—whereas it is less likely on the theory he is trustworthy. This is because, of the two classes of people, the trustworthy and the untrustworthy, fewer in the former class have criminal records than members of the latter class do. If no trustworthy people had criminal records, your hypothesis would be all but refuted by the discovery of a criminal record—your consequent would be as low as represents the merest remaining possibility that there may yet be some exceptional person not yet documented who has a criminal record and is still trustworthy. So if that were the case, your theory's consequent would be greatly reduced indeed. In reality, though, many people with criminal records are nevertheless trustworthy, so it would not be reduced quite so far, only as far as represents the actual likelihood of such a person still being trustworthy. On the other hand, the lack of a criminal record is not unexpected on the alternative hypothesis that your neighbor is untrustworthy, since many untrustworthy people lack criminal records. Thus the logic of evidence is often not as straightforward as many think.24
Assume (merely for the sake of argument) that the following represents the statistically determined facts (by, say, a very large scientific study):
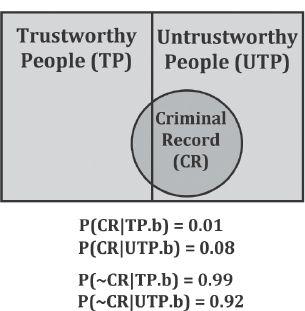
By this account, the consequents of both hypotheses would be small. But it is only the ratios that matter to the outcome. And in this account, having a criminal record is eight times more likely on the “untrustworthy” hypothesis than on the “trustworthy” hypothesis, whereas not having a criminal record makes very little difference on either hypothesis. Hence, the absence of a criminal record reduces the consequent for ~h (untrustworthy) by only a tiny amount (and for h, an even tinier amount), whereas the presence of a criminal record reduces the consequent of h(trustworthy) eight times more than the consequent of ~h, the same as if the consequent for ~h were 1 (100 percent) and the consequent of h were 0.125 (merely 12.5 percent), which is a huge difference.
In such a way, evidence can reduce the consequent probability of your hypothesis, and sometimes reduce it greatly, even though that evidence doesn't even contradict your theory—just as having a criminal record and being trustworthy are not mutually contradictory. As long as you lower your consequent to reflect the fact that some of the evidence is less expected on your theory than alternatives, your reasoning will be sound. But if you don't take this into account (and historians who avoid BT often do not), your reasoning will be fatally flawed. Thus using BT will often uncover errors otherwise overlooked, such as ignoring the effect of different degrees of fitness between evidence and theory—rather than considering only evidence that directly ‘contradicts’ your theory as counting against it (a mistake too many historians make). Remember, you may already be making this mistake. So you can't avoid it by avoiding BT.
In fact another way to analyze consequent probabilities is simply to think of them as in ratio to each other (see page 284). As in the above case, all that really mattered was that P(CR|UNTRUSTWORTHY) = 8 × P(CR|TRUSTWORTHY), since no matter what probabilities you use for P(CR|UNTRUSTWORTHY) and P(CR|TRUSTWORTHY), as long as this ratio of eight to one is maintained, the result using BT will always be the same. Thus you don't need to know these probabilities at all, just what the ratio between them is. Sometimes knowing the latter even tells you the former. For example, if several witnesses report seeing a series of bright lights in the sky moving relatively quickly and changing color but staying in formation (and they saw nothing else and no other evidence turns up), there are three likely explanations: aircraft flying in formation, an aerial flare drop, or a meteor breaking up in the atmosphere. If only one in a hundred meteors breaks up (and thus looks like what these witnesses reported), and aircraft never look like that (never being that bright), but flares almost always look like that, then you can say the evidence is a hundred times more likely on the “flares” hypothesis than on the “meteors” hypothesis, and millions of times more likely on the “flares” hypothesis than on the “aircraft” hypothesis. If flares always look like that, then P(e|FLARES) = 1; and if aircraft produce that same evidence millions of times less often, then P(e|AIRCRAFT) < 0.000001 (in other words, one in a million at best); and if meteors produce that evidence only a hundred times less often, then we have P(e|METEOR) = 0.01 (or one in a hundred). But whether thinking in ratios like this, or analyzing the problem in any other way, the question is always the same: how often does a particular cause (h) produce the kind of evidence you have (e)? That's the consequent probability.
Consequent probability and historical contingency
Like the future course of the Mississippi River, predictions entailed by a hypothesis are always to some extent (and in some cases entirely) generic rather than specific. This is especially the case in history. The resulting probabilities are always conditional on a large set of other hypotheses. Most of these consist of ‘background knowledge’ (regarding the nature of the world, and of people, cultures, and contexts), which are hypotheses so well confirmed that their probability of being true is well above 99 percent. But some are hypotheses regarding historical contingencies beyond our ken. For example, in science a hypothesis may predict what observation will be made in what contexts, but it doesn't predict exactly when and by whom. Thus we can safely ignore such specific details as “exactly when and by whom” when estimating consequent probabilities. The same follows for hypotheses about history.
Specifying the ‘type’ of evidence to expect in this way allows wide ranges of possible outcomes, such that any one of those outcomes can be accounted likely if it occurs. Thus the probability that an observation would be made by a specific scientist on a specific date, which probability will always be extremely low, can be left out of account. So if A, B, C, etc. are different scientists making the same kind of observation and on different dates, a hypothesis might predict that P(A or B or C…ad infinitum|h.b) = 100%. In other words, even though P(A|h.b) = 0.000…0001 (since the probability of that observation being made by that specific scientist on that specific date will be exceedingly small), we are only interested in P(A or B or C…ad infinitum|h.b). Thus h does not predict exactly what evidence will appear, only what type of evidence will appear (what sort of thing some scientist will see on whatever date).
History entails many other kinds of disregarded contingencies like that. For example, that the Gospel according to Mark came to be attributed to “Mark” rather than to, let's say, “Timothy,” may be a mere accident of history that makes no difference, since a particular hypothesis might only predict that there would be some such document whatever the attribution. Likewise the specific content of such a document: there are countless different ways the Gospel of Mark could have been written, countless different stories and constructions and word choices and sentence structures. Most hypotheses don't predict these exact details, only what sort of contents should be there. The same goes for all evidence of any kind. One must thus distinguish ‘predictions of exact details’ (which BT does not concern itself with in this case) from ‘predictions regarding the type of evidence to expect.’ I'll provide a more technical demonstration of the validity of this distinction in chapter 6.
But you must be certain the issue is of the expected type and not a required specificity. In some cases, a disregard of contingency, such as expressed by P(A or B|h.b) = 100%, will not be valid. As with the example of the trustworthy neighbor: defining e in such a way as to entail P(CR or ~CR|h.b) produces invalid results, since both consequents would then be 100 percent (because the probability that anyone, trustworthy or not, would either have or not have a criminal record is by definition 100 percent), when in fact the presence of CR (a criminal record) makes a huge difference in the consequents (and the absence of CR, a small one). So when a particular contingency becomes more likely on one hypothesis than another, it can no longer be disregarded. For example, one hypothesis might predict that the Gospels would all be attributed to a disciple (and Mark, not being a disciple, would thus be an unexpected attribution), in which case P(e|h.b) would have to be lowered due to the evidence not being as expected. Or it could even be the other way around. When near enough to the events related, inventing a nonexistent author is always safer and thus more likely on a hypothesis of fabrication, because a nonexistent author won't be around or have living relatives who could gainsay the claim that he'd written any book, much less that one—hence, on a hypothesis of fabrication within that time frame, we should more expect attributions to people who can't be precisely identified or who don't even exist, in which case P(e|h.b) would be raised, not lowered. But either way we have a differential prediction we must account for. Of course, that difference in probability might also be small. It might even be so small as to be washed out by an a fortiori assignment of probability (which I'll discuss later) and therefore ignored on that ground instead. Likewise, such a difference in consequents might only occur for hypotheses whose prior probability is vanishingly small, which are already thus disregarded on that ground (as I explained on page 70). Otherwise, when two hypotheses make different predictions regarding the exact contents of e, as long as both hypotheses are viable (and thus not excluded on priors) and the difference predicted is large (and thus has a significant effect on consequents), the distinction must be included in your estimates of probability.
The role of conditional probability
All these probabilities are conditional on b (our background knowledge). Thus, just as with our priors, we base our estimates for the consequents on what we know about the world, people, the culture and historical context in question, and everything else. This means there are four ways to misuse the evidence. You can put things in b or e that shouldn't be there, or fail to include things in b or e that should be there. Both b and e should only contain facts every reasonable expert can agree on. Contentious claims, speculative suppositions, hypotheses that can't produce an expert consensus, and things that aren't even true should not be considered as either evidence or background knowledge when estimating probabilities in BT, although the mere fact that an expert disagreement persists on some point can itself be reckoned as knowledge or evidence. Background knowledge ideally represents the established consensus of experts, which can include a consensus that there is no consensus; while the evidence represents the facts that everyone agrees need explanation.
This also means you cannot exclude facts of either kind. Abusers of BT often attempt to argue in a vacuum, pretending a great many things we all know (the complete contents of b) aren't known, merely to generate a result they like. If we know a vast number of miracle claims have been established to be fraudulent, erroneous, or inaccurate (and we do), we cannot pretend otherwise. We must take this into account when estimating the prior probability of a genuine miracle. Because even if we are personally certain that some miracles are genuine, we still know for a fact most miracle claims are not. Therefore, we must accept that the prior probability of a miracle claim being true must still be low. Likewise, BT can be abused by excluding facts from e that substantially affect the consequent probabilities. The fact that the early growth of Christianity was exactly comparable (in rate and process) to other religious movements throughout history is a fact in evidence that significantly challenges the claim that Christianity had uniquely convincing evidence of its promises and claims.25 Likewise, the fact that medieval Christians became as depraved and despotic as peoples of any other faith is unlikely on the hypothesis that they had any more divine guidance or wisdom than anyone else has ever had. Similarly, the frequency of admirable new ideas among them was no greater than among many other cultures (who came up with many admirable ideas of their own), so they cannot claim any greater inspiration, either.26
Thus any fact in evidence that is hard for your theory to explain, or that is more likely on another viable theory, must be included in e. This also means it is not logically valid to exclude evidence from e by the mere device of inventing an excuse for it. Because any such excuse must necessarily lower the prior probability of your original theory, due to the simple fact that a theory without that excuse must have a nonzero prior—because it is logically possible, and indeed may even be the more plausible—so a theory with that excuse must have a prior that is smaller. This is because the prior probability of either theory being true must equal the sum of the prior probabilities of each one being true separately. For example, if theory A includes explanation D and excuse C, and theory B also includes explanation D but excludes excuse C, the prior probability of ‘explanation D’ (with or without C) equals the sum of the prior probabilities of A and B. In other words: P(D) = P(A) + P(B).27 So if P(B) is any nonzero value (and we know it always must be), then P(A) must be less than P(D) by exactly that amount. In other words: P(A) = P(D) – P(B). Thus adding C always reduces the prior probability of D. In fact, unless you have evidence supporting the inclusion of the excuse (C) over its exclusion (which means evidence other than the evidence that you invented C to explain away), then including C necessarily halves the prior of D—since with no evidence confirming C or ~C the principle of indifference entails that the probability of either must be equal (because for all you know either is as likely as the other), which means a probability of 0.5. All probabilities must be conditional on what you know at the time, so if you know nothing as to whether it would be higher or lower, then so far as you honestly know, it's 0.5. And if there is evidence against C (either against C specifically or against excuses like C generally), then including C will reduce the prior of D by more than half. Since then the probability of either C or ~C is no longer equal but tilted in favor of ~C. This iterates for every excuse added. Thus, attempting to salvage a hypothesis by inventing numerous ad hoc excuses for all the evidence it doesn't fit will rapidly diminish the probability of that hypothesis being true (which happens to be the logical basis for Ockham's Razor—as I'll explain in the next chapter, page 104). Only if you can adduce convincing evidence that such an excuse was indeed operating will including it have a negligible effect. For instance, if you can prove that D without C is actually very rare or unlikely, then P(A|b) will be close enough to P(D|b) as to make no significant difference to the outcome. And either way, we still don't remove the evidence thus “explained away” from e; we merely assign that evidence a high consequent on h (since C will have been crafted to have exactly that effect: to make the evidence more likely on h than would be the case without C). This is what prevents ‘gerrymandering’ a cherished theory to fit just any body of evidence. Which makes BT an important corrective to bad historical reasoning.
The problem of subjective priors
The objection most frequently voiced against BT is the fact that it depends on subjectively assigned prior probabilities and therefore fails to represent objective reasoning. The same can be said of the consequent probabilities. But insofar as this objection is true, it condemns all reasoning, not just BT. The only difference is that BT makes this reliance on subjectively assigned priors apparent, whereas all other methods of argument simply conceal it. The fact remains that we always base our arguments on assumptions about the inherent likelihood of whatever we are arguing for or against. If that is a defect that condemns any method, it condemns them all.28
But the subjectivity of priors is actually not a problem for BT.29 The fact of their subjectivity does not prevent us from producing conclusions that are as objective as can possibly be, given the limits of our knowledge and resources. Because subjective does not mean arbitrary.30 You must have reasons for your subjective estimates, so you must confront what those reasons are.31 And in defending your conclusion to anyone, you must be able to present those reasons to them, and those reasons had better be widely convincing. If they aren't, you need to ask why they ever convinced you. If you have no such reasons, then your priors are irrational and you need to change them until they are rationally founded. And if you do have sufficient reasons, you need to ask if those reasons will be accepted by other reasonable people. That would then actually make them objective, since by definition objective reasons will be accessible and verifiable to all reasonable observers, who will thus all come to the same subjective estimate.
You can still warrant your own belief in a conclusion if you have access to evidence others don't, but in such a case you need to acknowledge and accept the consequences of that fact. One of those consequences is that whether others accept your testimony will be based only on the evidence available to them. For example, you may be certain you visited an alien spaceship last night, but everyone else only has a vast body of background knowledge establishing that most (if not all) such experiences are hallucinatory or fabricated. You have to respect the fact that they are fully warranted in rejecting your testimony—until such time as you can prove your experience was genuine in a way that so many others were not, with evidence that others can observe (I'll discuss this point further in chapter 6, page 210). Likewise, if you accept or reject different epistemological assumptions, then you cannot persuade anyone with any argument (much less BT) until you either adopt their epistemological assumptions or a subset of them that you share in common (enough to build a valid argument on), or first convince them to adopt your epistemology instead. None of those scenarios are relevant to the present case. This book is not written to convince adherents of radical epistemologies (such as reject the axioms and rules discussed in chapter 2). And like all professional historians, I am only interested in objectively grounded premises (in accord with the first axiom).
So how do we get those? You may be hesitant to assign probabilities because it seems arbitrary and subjective. But the point is to translate your actual beliefs into a more convenient language. You already have those beliefs. So translating them into numbers does not make them any more arbitrary and subjective than they already are. And they are rarely as subjective as you might think. When you say a claim is plausible, you are saying it has a high enough prior probability to consider it. When you say it's implausible, you are saying it has a prior probability low enough to dismiss it. Whenever you say one theory explains the evidence better than another, you are saying it has a higher consequent probability than another. And so on. All these statements will entail numerical equivalents, which are often objectively reasonable.
Given any belief about the past, you must believe it has some probability of being true or false. And given any probability P, you logically must believe P is either 0 or 1 or some value in between. Only if the claim assigned this probability cannot be denied (if its truth is logically necessary) can P = 1, and only if it literally cannot be true (if its truth is logically impossible) can P = 0, because everything else has some nonzero chance of being true or false, as explained in chapter 2—and as also explained there, even those rare assignments of 1 and 0 cannot really be warranted, since we can sometimes be wrong about what's logically necessary or logically impossible. So nearly every claim has some probability between 0 and 1. Therefore, if P pertains to any claim about history, then P must be some value between 0 and 1. Where between? If you genuinely have no reason to believe P is higher or lower, then that entails that you believe P is 0.5. The latter is simply a translation of the former into a different language. If you disagree with that conclusion, then you either do so irrationally or rationally. If irrationally, then you are no longer participating in valid historical argument. You can safely put this book down. We have no use for you. But if you have a rational objection to the conclusion that P is 0.5, then you must have a valid reason to make P higher or lower, in which case you should raise or lower P accordingly. This is true by definition. If you have any objective reason to believe P is not 0.5, then you must believe it is either higher than 0.5 or lower than 0.5.
And when your language gets more precise (and you start using adverbs like “slightly,” “very,” or “extremely”), this, too, entails numerical equivalents. For example, “slightly more likely than 50%” never means 90%, or even 70%; typically it means no more than 60% and in some contexts might mean no more than 51%. But even if for some strange reason you actually mean by “slightly more likely than 50%” a 90% likelihood, then that is what it means to you. So you still have a probability. For any ordinal ranking of likelihood, there is some probability that you already mean by it, into which it can be translated. This won't be the precise and only probability you can mean by it, but there will be an upper and lower bound of the range of probabilities that you mean by it, and you can use either depending on which you need for the occasion (whether the lower bound or the upper) in order to build an argument a fortiori (which method I shall discuss on page 85). And the same goes for any other ordinal assignment, like “very likely” or “almost certain” or “quite probably” and so on down the line.
BT or not, either you could back up all these adverbs and assertions when you used them before, or you couldn't. If you couldn't, then you were being as subjective as you could ever accuse BT of being. But if you could back them up, then you can in BT just as well. So BT is no more subjective than any other form of historical argument. And when used properly, it is as objective as any historical method ever could be. Historians all have some idea of what was typical or atypical in the period and culture they study, and they can often make a case for either from the available evidence. If they can't, then they must admit they don't know what was typical, in which case they can't say one theory is initially more likely than another. The prior probabilities are then equal. Likewise, if historians can't defend a particular estimate of consequent probability, then they need to lower or raise that consequent until they can defend it. And if they can't defend any value, then they cannot claim to know whether the evidence supports or weakens their hypothesis (or any other hypothesis for that matter). This follows whether historians use BT or not. Because if they can't defend any probability assignments in BT, then its probabilities are all 0.5, and then its conclusion is necessarily always 0.5, which entails the theory in question only has a 50/50 chance of being true (or, for that matter, false). Since BT is formally valid and its premises would then be inarguably sound (because being conditional on what the historian knows, that's exactly what those probabilities must be if the historian can adduce no evidence for any other values), any argument that contradicts that conclusion (that the theory in question is as likely false as true) must be invalid or unsound. Likewise for any values other than 0.5 that a historian can make any defense of. The consequences of this are laid out in the next chapter.
So you might as well use BT. Because you can't get any better result with any other method.
Arguing a fortiori
There are several tricks to ensure your use of BT is adequately objective. The most important is employing estimates of probability that are as far against your conclusion as you can reasonably believe them to be. This is called arguing a fortiori, which means “from the stronger,” as in “if my conclusion follows from even these premises, then my conclusion follows a fortiori,” because if you replaced those estimates with ones even more correct (estimates closer to what you think the values really are), your conclusion will be even more certain.
This eliminates the problems of inscrutability and underdetermination. The exact probabilities in BT will often be inscrutable (meaning incalculable or unknown to us), but a fortiori probabilities will not be inscrutable. Their assignment will often be objectively undeniable. You might not personally know what the exact probability is of a mile-wide asteroid striking the earth tomorrow, but you certainly know it is less than one in one hundred (in fact, a very great deal less, since not even one such asteroid hits the earth every year, much less three of them). Thus the inscrutability of the actual probability does not entail the inscrutability of an a fortiori probability. Any conclusion reached with BT using such a probability will commute the a fortiori qualifier from the premises to the conclusion; for example, if we assign a prior probability of “x or less,” then the conclusion will be some value “y or less,” in other words, “possibly less, even a great deal less, but certainly not more.” Thus we can establish a conclusion objectively with BT even when the actual probabilities are inscrutable.
Likewise, underdetermination refers to the problem that there are infinitely many theories that can explain all the same evidence just as well as ours does, and most of them we haven't even thought of (so we can't even say we've ruled them out). But since BT conclusions are conditional on present knowledge, theories we haven't thought of yet make no difference to the result. Such theories do not exist in b and thus have no effect on what we are entitled to believe given what we so far know. When we know something different, our conclusion about what's warranted may change, but only then (see chapter 6, page 276). And of theories we have thought of, most by far have a prior probability we know to be vanishingly small (like the ubiquitous “aliens did it”), while the remainder we consider. That's why adding up the priors of all the thousands of conceivable fringe theories will still only get us a total much less than one percent. Strictly speaking, we would still have to plug that into our equation. However, if we are using a fortiori estimates of the prior probability of our favored theory, then the collective priors of all conceivable fringe theories are washed out, buried under the much more enormous percentage by which we have already underestimated our own theory's prior. That's why we don't have to give them any further thought (unless we want to).
Arguing a fortiori can also save us a great deal of labor or help us identify where more labor would be worthwhile. The vast effort involved in trying to collect and analyze all the data necessary to get increasingly accurate estimates of probability is unnecessary if we don't needincreasingly accurate estimates. If we can fully justify an a fortiori probability on a sound representative sample of the data (or an adequate preliminary survey of it) such that we can demonstrate that any continued labor will only push the result even further in favor of our conclusion, and yet our conclusion is already more than adequate to warrant confident belief, then we don't need to continue the inquiry further (unless we want to).32 Conversely, if an a fortiori conclusion is not yet strong enough to warrant confidence, it nevertheless shows us in what direction further data will take us, thus giving us a reason to pursue that further inquiry precisely to see how much more confidence we can warrant in the conclusion.
Arguing a fortiori in BT also answers the objection that historians don't have precise data sets of the kind available in the sciences. All probabilities derived from properly accumulated data sets have a confidence level and a margin of error, often expressed in various ways, like “20% +/-3% at 95% confidence,” which means the data mathematically entail there is a 95% chance that the probability falls between 17% and 23% (and, conversely, a 5% chance that the probability is actually higher or lower than that). Widening the margin of error increases the confidence level according to a strict mathematical relationship. This permits subjective estimates to obtain objectively high levels of confidence. If you set the margin of error as far as you can reasonably believe it to be, then the confidence level will be as high as you reasonably require. In other words, “I am certain the probability is at least 10%” could entail such a wide margin of error (e.g., +/-10% on a base estimate of 20%) that your confidence level using that premise must be at least 95% (a confidence level that with most scientific data sets would entail a much narrower margin of error). Again, you may not have the data to determine an exact margin and confidence level, but if you stick with a fortiori estimates, then you are already working with such a wide margin of error that your confidence level must necessarily be correspondingly high (in fact, exactly as high as you need: i.e., if the margin is “as wide as I can reasonably believe” then it necessarily follows that the confidence level will be “as high as ensures my belief is reasonable”). Thus precise data is not needed—unless no definite conclusion can be reached with your a fortiori estimates, in which case you have only two options: get the data you need to be more precise, or accept that there isn't enough data to confidently know whether your theory is true. Both will be familiar outcomes to an experienced historian.
Indeed, “not knowing” is an especially common end result in the field of ancient history. BT indicates such agnosticism when it gives a result of exactly 0.5 or near enough as to make little difference in our confidence. BT also indicates agnosticism when a result using both margins of error spans the 50% mark. If you assign what you can defend to be the maximum and minimum probabilities for each variable in BT, you will get a conclusion that likewise spans a minimum and maximum. Such a result might be, for example, “45% to 60%,” which would indicate that you don't know whether the probability is 45% (and hence, “probably false”) or 60% (and hence, “probably true”) or anywhere in between. Such a result would indicate agnosticism is warranted, with a very slight lean toward “true,” not only because the probability of it being false is at best still small (at most only 55%, when we would feel more confident with more than 90%), but also because the amount of this result's margin falling in the “false” range is a third of that falling in the “true” range. Since reducing confidence level would narrow the error margin, a lower confidence would thus move the result entirely into the “true” range—but it would still be a very low probability (e.g., a 52% chance of being true hardly instills much confidence), at a very low confidence level (certainly lower than warrants our confidence).
This method of using a fortiori probabilities was illustrated earlier in this chapter with both examples of the sun going out. Exact data were not necessary to determine what conclusion is obviously correct. The frequency of such claims (of wildly unlikely astronomical events) being true (rather than, for any of various reasons, false) is certainly far less than one in one hundred, which entails the probability that the sun went out in the first century is certainly far less than the one in ten thousand we concluded with. That conclusion is objectively true. Yet at no point did we need to know the exact ratio of true to false claims in the category of wildly unlikely astronomical events.
Mediating disagreement
There is no rational basis for rejecting the validity of BT, and, as so far shown, no reasonable basis for rejecting its application to history (and chapter 4 will prove that), which leaves disagreements over its application. These will consist of objections to the correctness of its use (which ought to be resolved not by abandoning BT but by using it correctly) and objections to probability assignments and their derivation from accepted background knowledge. The latter are exactly the kinds of debates historians need to be engaging in. Because by avoiding BT they are often avoiding the real issues of contention between them, and thus failing to address the actual defects of their own methodologies. The result is a chaos of opinions battling each other as claims to fact, with no progress in sight (such as surveyed in chapter 1). But if the difficulty of subjectively arriving at objective probability estimates is confronted head-on, then progress can be made. Even if that progress only amounts to a greater consensus on our mutual uncertainty, it would still be progress.
Most disagreements arising from the subjectivity of probability estimates are of no relevance to progress in the field anyway. For example, if two scholars disagree over the correct prior, one insisting it must be a thousand times smaller than the other is sure it is, yet on either estimate the conclusion is still more than 99 percent certain (i.e., P(h|e.b) > 0.99), then their disagreement makes no relevant difference. Both historians would consider the hypothesis decisively confirmed. Only when disagreements over probabilities make for a different conclusion do those disagreements matter. And when that happens, each scholar is obligated to present the evidence establishing that his estimate is correct and that the other is not. Often such an exchange will conclude with both scholars agreeing on an a fortiori estimate somewhere in the middle as the only estimate that can be objectively supported by the evidence. The result will be agreement on the estimated probabilities, and, therefore, agreement on the conclusion. This is one of the reasons historians should use BT: precisely because it will provoke such debates and discussions, resulting in greater clarity, better-supported premises, and wider agreement.
Indeed, to begin making progress, you have to start somewhere. Imagine a situation where all observers start with different estimates and then acquire exactly the same total knowledge; that is, each observer knows exactly all the same things as every other observer. There could then be no explanation for why they would still differ in their estimates, because, if they only employ valid arguments, working from exactly the same information, then they would have to agree. It would be logically impossible for anyone to reach a different conclusion under those conditions. So if they still came to a different conclusion, we would have to identify irrationality as the culprit, and then work out who is guilty of it by examining (“on the couch,” so to speak) why each observer still comes to different estimates. I think in practice, as knowledge sets converge, rational observers (those who only employ logically valid arguments) will converge in their probability estimates, and even where they continue to differ, the difference will become less significant (as in the manner described above). One scholar might disagree with another yet still accept the other's estimates as approaching what's reasonable, especially if their margins of error overlap. Hence, they might consider their differences too insignificant to signal either of them as irrational (unless they can identify actual instances of invalid reasoning).
More likely any outstanding disagreements would be due to remaining differences in their knowledge sets, especially knowledge not easily communicated or shared (such as personal childhood memories and influences). Even when that difference comes from years of study in a particular area that one historian has undertaken but others have not, since that will still have been the study of actual objective facts, that historian should still be able to collect and communicate any relevant data culled from it whenever claims based on it are doubted. Thus, if significant differences in estimates exist between experts, the solution is not to abandon BT (since those differences will remain and covertly influence all their arguments anyway), but to increase communication through debate and information sharing so their respective bodies of evidence and background knowledge approach agreement and so their reasoning will approach greater and more consistent validity. Which, of course, historians should be doing anyway.
The conclusion must be that if you cannot validly formulate your argument according to Bayes's Theorem, then either you don't know what you're doing or your argument is invalid or unsound (as we'll see in the next chapter). Therefore, a good method is to attempt such a formulation for any argument you may ever make as a historian and then identify what problems arise with the attempt. Because those problems will often expose underlying assumptions you had already been making or relying on that are not as sound or secure as you may have assumed. Or, you will discover how you are misusing BT, and by correcting that mistake you will thus improve your competence in applying it.
I will say more on the matter of resolving disagreements with BT in chapter 6 (starting on page 208). But ultimately, any argument against the applicability of BT in any given case can only amount to either: (1) a declaration that the data is too scarce to come to any conclusion (in which case a proper use of BT will prove this and thus BT will not be inapplicable after all); or (2) a declaration that BT has been misused (in which case the proper response is not to abandon BT but to use it correctly, so this cannot be an argument for its inapplicability); or (3) a declaration that the user has employed the wrong data, either leaving something out of account or including something false or inappropriate, in which case, again, the proper response is to redeploy BT with the correct data (which will produce a conclusion all rational parties must agree with, so even this cannot be an argument for its inapplicability). In terms of (1), (2), or (3), continued honest debate will lead to agreement by all rational parties as to the premises—regarding allowable margins of error, for example.33 Once everyone agrees upon the premises, they must agree with the conclusion, as it then follows necessarily. If, despite all this, someone continues to insist upon the inapplicability of BT, there is not likely to be any rational ground for his opposition. Usually at this point objections to BT amount to a stolid refusal to accept rational conclusions that one is emotionally or dogmatically set against, which is definitely not a valid objection to BT's applicability.
One might still object not to BT's applicability, but to its utility. That is, we can acknowledge that BT is valid and that BT arguments in history are sound, while still claiming that BT adds no value to already-existing methods, or even makes things harder on the historian than they need to be, in terms of both learning curve and time-in-use. But this objection will be more than amply met in the following chapters. In general, there are three points to make. First, insofar as historians are doing their job as professionals, they should already be devoting considerable time to mastering the relevant methodologies. And yet learning BT is no more time-consuming than learning existing methods of historical reasoning, and as existing methods are significantly flawed (as will be shown in coming chapters), the time spent learning the latter can be redirected toward learning the former (or rather, new versions of the latter that have been reformulated in terms of the former), resulting in no net loss in learning time. Second, insofar as historians are not spending time learning logical methods of analysis and reasoning, they ought to be, otherwise they cannot claim to be professionals. Complaining that learning how to think properly is too time-consuming is not a complaint any honest professional can utter in good conscience. Third, when it comes to time-in-use, in most historical argumentation BT does not have to be very complicated or time-consuming at all, except in precisely the ways all sound and thoughtful research and argument must already be. And in the few cases where BT arguments need to be more complicated, this will be precisely because no other methods exist to manage those cases. Because if they did, and they are logically valid, then they will already be covertly Bayesian anyway (as I'll demonstrate for a number of cases in chapter four). When a problem is complicated, it will always be complicated no matter what tools you use to analyze it. Attempts to avoid that fact can only result in lazy or unsound thinking, and that is certainly not a good excuse to avoid BT.
Which brings me to a final point about the function of this book as a whole. I am pursuing two related objectives: first, to demonstrate when and why existing methods of historical reasoning are logically valid; and second, to provide a model of reasoning that can be directly employed in historical analysis and argument. The latter is methodological, the former is epistemological. But even the epistemological point is essential to vetting and developing new methodologies. Thus I shall explain in coming chapters how existing methods conform to Bayes's Theorem and only remain valid to the extent that they continue to conform to Bayes's Theorem. This then gives us warrant to trust those methods (by grounding them logically) even if we don't explicitly employ BT when we deploy them. That same analysis will also establish limits and guidelines for any effort to expand, improve, or modify existing methods, or develop new ones. But this still means that once a method's soundness has been established by BT, you don't have to use BT. You can simply apply the method it has validated. BT would remain a tool for criticizing when that method is being used invalidly, but as long as that method is used validly, its connection to BT need no longer be discussed.
So BT is not necessarily a replacement for other methods, but just the structure on which they must rest. And yet BT remains a very useful tool in its own right. As shown by the opening example of this chapter, most historical reasoning already implicitly conforms to it. By seeing this and rendering it explicit, casual reasoning becomes more refinable, testable, and critical. This often requires no math at all, but just an understanding of how the relative weights of certain probabilities entail a conclusion, and thus which probabilities you need to look at, and which weights have which results. And even when you need the math, you won't necessarily need to show it in any end result. You can just translate what the equation is saying into plain English and publish the latter. And the math you'll need is almost never as complicated as it is in the sciences, or even archaeology (where rather advanced Bayesian methods are already being deployed). It's usually very simple arithmetic, using basic a fortiori estimates. Thus its application in practice simply isn't difficult or time-consuming enough to oppose its use in history. To the contrary, as both a method in itself and a practical epistemological tool, its utility in history is considerable. The following chapters will be devoted to establishing that.
Canon of probabilities
To ensure the greatest consistency and the least contention, we can conform our inputs to a table of just eleven probabilities representing common historical judgments, which you will routinely find spelled out in English with the same or equivalent wording throughout professional literature in the field.34 Only where and when we can convincingly demonstrate a probability more precise need we deviate from the following canon:
“Virtually Impossible” = 0.0001% (1 in 1,000,000) = 0.000001
“Extremely Improbable” = 1% (1 in 100) = 0.01
“Very Improbable” = 5% (1 in 20) = 0.05
“Improbable” = 20% (1 in 5) = 0.20
“Slightly Improbable” = 40% (2 in 5) = 0.40
“Even Odds” = 50% (50/50) = 0.50
“Slightly Probable” = 60% (2 in 5 chance of being otherwise) = 0.60
“Probable” = 80% (only 1 in 5 chance of being otherwise) = 0.80
“Very Probable” = 95% (only 1 in 20 chance of being otherwise) = 0.95
“Extremely Probable” = 99% (only 1 in 100 chance of being otherwise) = 0.99
“Virtually Certain” = 99.9999% (or 1 in 1,000,000 otherwise) = 0.999999
Obviously, you will often be able to argue for other values between these, or values vastly lower or higher than the extremes given. But unless you can be more precise, you should only employ the values here (or from some comparable canon) that support your conclusion a fortiori so that any adjustments in the direction of the correct values will only make your conclusions stronger.
Of course, we can always apply other canons. For instance, my assignment of the phrase “extremely improbable” to one in one hundred odds may fit how historians commonly speak, but not other contexts. No one would get into a car that had a one in one hundred chance of exploding, so we usually wouldn't say that that outcome is “extremely improbable.” An extremely probable conclusion in history is therefore typically not anything anyone would bet his life on. How we decide what someone “means” when they use nonmathematical phrases to express probability is therefore context-dependent. Thus it's useful to look for measurable benchmarks within the same context and extrapolate from there. Before saying “I'd bet my life on it,” what improbability of a car's exploding would you deem acceptable before getting into it?—and you can't say that probability must be zero, because it never is.
You can translate all ordinal benchmarks of confidence into probabilities by measuring them against known odds like this. If the odds were one in one hundred that a car you got into would explode, how “confident” would you be in that car's safety? Answer that and you've just ascertained what probability you mean by that expression of confidence. Likewise the other way around. If while on a basketball court you are only slightly confident you can make a hoop shot from where you are standing, how often does that mean you would make it if you tried it a dozen times? Once or twice? You've just ascertained that “slightly confident” means, to you, about one in six odds, or 17 percent. Or do you mean a little more than half the time, like maybe seven shots out of twelve? You've just ascertained that “slightly confident” means, to you, about seven in twelve odds, or 58 percent.
You might mean different things in different contexts, but then all you need do is find comparable benchmarks within each context, in order to build another translation key. All your nonmathematical expressions will still cover a range of probabilities, not just a single probability. But explore the limits on either side (e.g., how many hoop shots out of twenty, or a hundred) and you might find that to you “slightly confident” never means less than 51 percent or more than 66 percent, so it therefore means “between 51 and 66 percent,” inclusively); or you might find you'd be “very confident” in a car's safety only if it exploded no more than once in a billion times, but you'd be just about as confident if if were once in a trillion, so “very confident” means to you “between one in a million and one in a trillion.” And so on. You can then pick the limit that corresponds to an a fortiori probability. This works even if you are translating phrases with words other than “confident,” like “sure,” “certain,” “credible,” “likely,” “believable,” or anything else. How “believable” is it, for instance, that in a friendly game of basketball you will make a regulation free throw? That will certainly be a function of how often you make them and how often you don't. Betting odds follow, and from that, a probability.
FROM BAYES'S THEOREM TO HISTORICAL METHOD
This chapter hopefully provided an adequate primer to Bayes's Theorem, at least as far as applying it to typical cases of historical argument. But one might still ask, does BT actually underlie all valid historical methods? Aren't there other valid methods that work better? To that question we now turn.