CHAPTER 16
Earlier, in Chapters 1 and 14, I stated that while my organization of this book’s content is approximately chronological by individuals in our story, there is a specialized area of mathematics and statistics—that of psychometrics and psychological testing—that seems more suited to being placed together, under one roof as it were. Some years ago (but still relevant), the journal Science cited the mental test as one of twenty discoveries that have shaped our lives forever (Miller 1984); and, hence, it needs attention all its own. The persons responsible for the invention and development of psychometrics and psychological testing were more focused on applying mathematical principles in new and important ways than on inventing original formulas and general processes. It is akin to ascribing your scholarly work to either pure (theoretical) mathematics or applied mathematics. The notables of psychometrics and psychological testing are decidedly in the latter group, dealing mostly with application. This chapter is devoted to describing these individuals and how their efforts contributed to quantification.
Quantification is both tangible and personal. Perhaps more than anywhere else, this is seen in the science of educational and psychological testing. It is decidedly personal, because we have all taken a test, and more likely, many of them. We know what they are like and realize that the test-taking experience is different from anything else described in this book. The events and inventions we have relived in these pages so far are, of course, amazing, but none of them engages our emotions directly like a psychological test.
With the test, we are vulnerable. It is a deep dive into our very nature and identity. An educational or psychological test looks into our brains—our achievements, aptitudes, beliefs, and opinions—and lays them bare for others to see. Making this very personal part of us public is scary because, before taking a test, we do not know how it will turn out. Upon learning the results, we can brag about them, hide them, or simply dismiss them. But, in all instances, we are directly engaging our emotions in the outcome. It is quantification up close and personal.
Our response is generally dependent upon the consequences of the assessment. When the stakes are high—such as with college admissions or when used in licensing and certification—our anxiety is correspondingly raised. When the stakes are low—such as when a marketer queries us about some opinion, we generally forget the experience almost immediately.
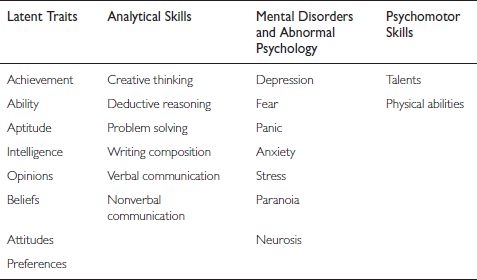
Although mental appraisal is most often associated with educational and psychological testing, it covers a broader range of issues than that, incorporating a concern for any kind of cognitive or psychomotor assessment. Actually, the types of tests that have psychometric properties are extensive, as shown in the list in Table 16.1.
Table 16.1 Illustrative kinds of mental assessments
Regardless of the type of assessment, we expect it to be accurate and thoughtfully done. Technically, these are concerns of validity and reliability. Psychometrics is the science of addressing such concerns of validity and reliability in cognitive measurements. Procedurally, it is the technical application of statistics and probability theory to address test development, test administration, and—most important—proper interpretation and use of a test’s results.
Significant, and often misunderstood, is that validity is not a feature of a test instrument; rather, it is a concern for the appropriate, meaningful, and useful application of the scores yielded by a test for a given decision. In high-stakes testing, such as when the test’s score is used for licensing or certifying an individual as competent in a given field (e.g., doctor, aircraft pilot, lawyer, certified public accountant, electrician), the validity of the decision is of paramount concern.
Further, establishing validity is complex. It is decidedly not a simple yes or no declaration. And, there is no single criterion or score for validity. Instead, validity is a matter of accumulating evidence to justify the decision made based on the yielded scores. Establishing validity is parallel to a lawyer making the case for the guilt or innocence of a defendant in a court case. It is justified by a preponderance of evidence, established anew with each circumstance.
Reliability, on the other hand, is a more tangible concept. It is an index calculated through mathematical determination of the consistency of a measure’s score, generally from one testing occasion to the next, although there are some mathematical shortcuts wherein an index of reliability may be determined from a single administration. Most often, reliability is seen in either of two types of evidence: (1) temporal stability, as seen by consistency across multiple testing occasions, or (2) internal consistency, wherein the individual elements of a test (e.g., the questions) are arranged mathematically into a matrix that shows their consistency. Further, evidence of reliability is a necessary, but insufficient by itself, requirement of validity.
From even this brief description, you can see that the discipline of psychometrics has a utilitarian focus. But this does not mean it is a narrow or limited field. Actually, just the opposite: psychometrics is multifaceted, encompassing many topics, including developing a test, concerns for test administration, accommodations for examinees with disabilities, guidelines for fair use, and especially stipulations to ensure that a test’s yielded scores are interpreted correctly and used properly.
Many of these issues are addressed in an industry-standard publication titled Standards for Educational and Psychological Testing (American Educational Research Association, American Psychological Association, and National Council on Measurement in Education 2014). In addition to the main topics of validity and reliability just mentioned, this publication gives direction to psychometricians for a host of related concerns, such as fairness to all test takers, how best to accommodate examinees with disabilities, and issues for test security. The standards are reviewed and updated every few years, and examining older editions gives a history of testing, especially regarding evolving conceptions of validity.
Of course, when reporting the results of most tests, especially school-based tests, the standard normal curve is used for interpretation. A very famous depiction of the normal curve is shown in Figure 16.1. About 1950, this picture was distributed as an Educational Service Bulletin (this one is in Bulletin No. 48 from The Psychological Corporation, the educational testing company founded by James Cattell, whom we’ll meet momentarily). These testing bulletins were sent to parents of schoolchildren to help in their understanding of various kinds of test scores. At the time, such informational bulletins were common.
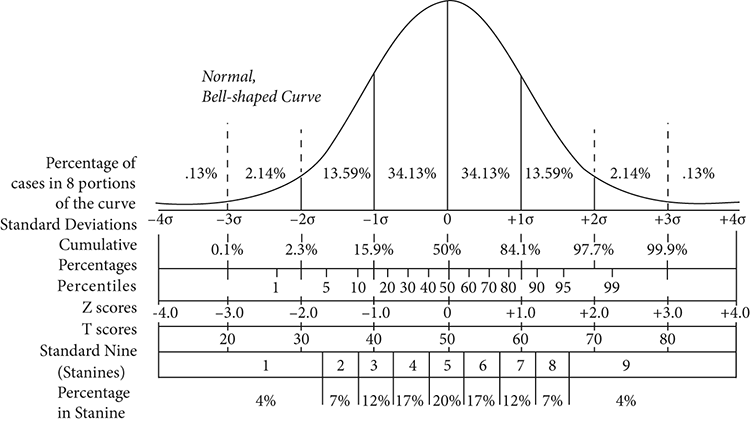
Figure 16.1 Educational service bulletin to parents, showing a standard normal distribution with many derived scores
(Source: http://commons.wikimedia.org/wiki/Category:Public_domain)
Below the normal curve, many types of derived test scores are given. Each scale has meaning for a different context. Among the scores presented are the standard deviations and the percentiles, quite familiar to us. Also shown are the z-scores and t-scores from the work of Gosset and Fisher. “Stanines” are yet another way to express test scores. For them, the full range of the scale is divided into nine standardized parts. The nine units were chosen because, at the time, only the values 0 to 9 could fit onto a punch card used for computer input.
The earliest documented use of testing on a large scale is with the Chinese Civil Service, which began its testing somewhere around 2000 bce. These assessments were written tests to gauge language competence for prospective civil servants. The testing continued for several hundred years, although substantive changes in focus and administration were made along the way. After several variations of the assessment program, these early exams apparently ended at about 1370 bce, when a new set of assessments, called the Imperial Examinations, were instituted. To take these imperial exams, candidates would sit in a small, isolated booth for at least 24 hours to prevent cheating. There, they would respond in writing to several questions of varying types, including asking them to compose a poem. Only a very few individuals passed, whereupon these achievers would progress to another set of tests. The imperial exams continued into the twentieth century, although numerous content and functional changes were made. Now, an entirely different set of examinations are used, but the practice of large-scale testing continues unabated.
Of course, large-scale testing is not confined to China. School-based achievement testing is used today in nearly every country. The current public school national assessment in the United States is the National Assessment of Educational Progress (NAEP; see National Center for Educational Statistics 2018). It is interesting, however, that NAEP assessment employs a complex administration procedure called “matrix sampling,” wherein no individual student takes the whole exam; rather, each student takes only a part of it. The parts are then combined to yield a score for a group of students, such as within a school district or a state. No individual student receives a score. Thus, states’ achievements may be compared, but those of individuals may not.
In Great Britain, there is compulsory testing in English, mathematics, and science at several ages along the educational track. Most exiting students also take the GCSE (General Certificate of Secondary Education) and its advanced levels to qualify for third-level education, and many take vocational qualifications (see British Government 2018).
While in Germany, five types of secondary schools are offered, each of which has a final examination. The most common of these is the Abitur (after Gymnasium (secondary schooling)) and the Mittlere Reife (after Realschule, or, in some states, Oberschulen or Sekundarschulen). These German school examinations are used by several other countries, too.
And many countries (more than sixty, at last count) participate in a cross-national testing with the TIMSS (“Trends in International Mathematics and Science Study”) and PIRLS (“Progress in International Reading Literacy Study”) assessment programs. The TIMMS, administered once every four years, measures how effective countries are in teaching mathematics and science. And PIRLS documents worldwide trends in reading for students in the fourth grade, as well as school and teacher practices related to instruction (see IEA International Study Center 2018). These assessment programs do allow for some kinds of international comparisons.
* * * * * *
Four persons were instrumental in founding modern testing: Francis Galton, Wilhelm Wundt, James McKeen Cattell, and Alfred Binet. Readers will recall that, earlier, we learned of Galton’s work in his Anthropometric Laboratory, where he tested physical attributes of adults and children and made his discovery of regression to the mean, which led to the invention of statistical correlation. In addition, owing to his wide-ranging application of statistics and measurement theory to cognitive assessment (particularly with his early attention to issues of validity and reliability), he is credited with founding the field of psychometrics. Further, he formed the notion that intelligence can be viewed as a psychological construct, thereby making it a variable for research. As readers likely know, intelligence is one of the most researched—and illusory—variables in all of science. Quite a list of accomplishments—and that is from just one of the four!
These four individuals worked mostly in the mid- to late nineteenth century, with the later years of their careers spanning into the twentieth century. All were interested in early explorations into mental illness in children, particularly with its accurate and meaningful assessment (i.e., validity and reliability), which gave a common focus to their efforts. Accordingly, psychometrics was an important feature in their work.
Now, on to describing the accomplishments of each of these founders of modern testing individually—if only briefly. In doing so, I will keep in mind our focus: namely, how these individuals contributed to advancing quantification as a worldview, particularly in bringing it to the lives of ordinary folks. Each of these individuals made numerous and extraordinary accomplishments in psychology and psychometrics, and I must necessarily leave out much of their work. Of course, entire biographies exist for each of them, and other sources offer a thorough account of their accomplishments.
Wundt was a German physician and philosopher who worked to identify children with mental illnesses. He was interested exclusively in exploring psychological issues, and he called himself a “psychologist,” possibly the first to do so. More than anyone else, he marked psychology as a distinct discipline, apart from biology and other fields of scholarship. Notably, he postulated a uniform theory of the science of psychology. Because Wundt was the first researcher to completely devote his career to psychological issues, he is often referred to as the “founder of modern psychology.”
And, for his innovative experiments on appraising psychological characteristics in children, he is also called the “father of experimental psychology.” To highlight his reputation, in 1980, the journal American Psychologist conducted a survey among historians of psychology to determine the most influential psychologists of all time. Wundt was the winner by a wide margin, even ahead of William James and Sigmund Freud.
Wundt was not subdued in his approach to the psychological research. Rather, he was a vociferous advocate for his new discipline of psychology, often encouraging students to the new field and giving frequent public lectures to educate the public at large. And he was a prolific writer. In 1874, he published Principles of Physiological Psychology, the first textbook on psychology, and he trained hundreds of students in psychology.
He believed that psychology should be studied with the same rigor as was brought to chemistry or the other hard sciences. He introduced the scientific method to the study of mental constructs and psychological issues with this direction: “the aid of the experimental method becomes indispensable whenever the problem set is the analysis of transient and impermanent phenomena, and not merely the observation of persistent and relatively constant objects” (Wundt 1904, vol. 1, 4). With this quote, he was the first to give scientific application to the study of psychology. Nearly all modern psychologists, whether in clinical practice or conducting research, have been influenced by Wundt.
Wundt was a professor at the University of Leipzig, which is one of the oldest third-level institutions in the world, having been founded in 1409. There, he created what is held to be the first formal laboratory devoted to studying psychological issues. His students went on to establish such centers for psychological research at many other universities, including Stanford University and Yale University. Today, they are commonplace on campuses throughout the world.
Much of his work focused on measuring mental chronometry, or more familiarly, reaction time—quite literally, the time it takes one to respond to stimuli. It is held that reaction time is related to general intelligence. With insight, Wundt said,
For each person there must be a certain speed of thinking, which he can never exceed with his given mental constitution. But just as one steam engine can go faster than another, so this speed of thought will probably not be the same in all persons. (Wundt, 1862, 264, as translated in Rieber and Robinson, 2001, 35)
Most reaction-time tests measure in seconds and even milliseconds. To make his measurements, Wundt called upon the English physicist and instrument maker Charles Wheatstone to make a machine for measuring reaction time. Wundt called it a “thought meter.” It is a clock with a pendulum device that has rods protruding down its sides. He set a calibrated scale behind the rods to measure how far they moved in a given time period (he used tenths of a second for his time increments). Wundt set the rods to begin at zero on his scale, and his reaction-time test began. A bell sounded. The subject’s task was to anticipate the bell, and when it rang, the subject would stop the rods by pressing a button as quickly as his or her reactions allowed. By seeing where the rods stopped, Wundt could read on his calibrated scale how many tenths-of-a-second tick marks they had passed. This was his innovative measure of reaction time, and although rudimentary, it was fairly reliable in its measurements. Over time, Wundt employed a variety of similar devices. One instrument he used is shown in Figure 16.2.
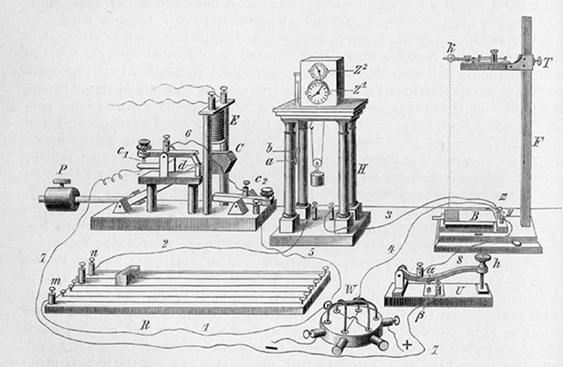
Figure 16.2 Version of Wundt’s reaction time “thought meter”
(Source: http://commons.wikimedia.org/wiki/Category:Public_domain)
Building from his belief that reaction time was correlated to intelligence, his work was instrumental in maturing the view that intelligence is itself a psychological construct that can be explored by cognitive means. He thought it could be assessed using both paper-and-pencil tests and, even more directly, experiments with reaction time. Prior to this view, researchers focused on simple sensory experiences, such as in Galton’s anthropometric investigations.
As a serendipitous consequence of his reaction-time experiments, Wundt also shed light on a classic problem in astronomy about measuring the density of the earth by noting differences in its position over time.
Interest in reaction time as a variable for assessment waned after Wundt (and slightly later, Cattell), but renewed attention to chronometric analysis arose in the late twentieth century. Modern scholars believe this kind of analysis has been fruitful in determining a general intelligence construct (the so-called Spearman’s g), as well as in its application in psychomotor and other physical tasks. For example, assessing reaction time in athletes with procedures much like Wundt’s thought meter is now common, although, of course, it is done for assessing physical abilities rather than mental constructs.
A leader in the revival of chronometric analysis was Arthur R. Jensen, a brilliant scholar at the University of California, Berkeley. Jensen worked in the mid- to late twentieth century (he passed away in 2012) and was renowned for his work in measuring individual differences. In his chronometric laboratory, he measured thousands of subjects from diverse backgrounds, noted relevant characteristics (like their age and other experiences), and presented his findings in hundreds of lectures, more than 200 articles, and six books. He summarized a lifetime of findings and drew several important conclusions in a book written near the end of his life, Clocking the Mind: Mental Chronometry and Individual Differences (2006). He was especially interested in exploring individual differences for school achievement, and he was an early advocate for extra funding and attention targeted to those with lower achievement and slower reaction time.
Following Wundt was his one-time assistant and advocate, James Cattell, who markedly advanced the discipline of psychology and psychological testing, especially in America. Cattell was born in Pennsylvania to a Presbyterian minister, who was himself an educated person and served as the president of Lafayette College, a small postsecondary institution in the town of Easton. Cattell spent his undergraduate years at that same college, where he studied English literature but also showed an ability and peripheral interest in mathematics. After graduating, but while still an undecided young man, he traveled to Europe, where he enrolled at the University of Leipzig. There he met Wilhelm Wundt, and they formed a friendship. Wundt convinced Cattell to study psychology and psychometrics, and, in doing so, Cattell found his calling. He excelled at his studies, and as a nascent researcher under the advising of Wundt, he wrote his doctoral dissertation (in German) on psychometrics. It was a first on the topic, and it set him apart from those studying more usual subjects.
The distinction of his dissertation led to a short-term lecturing appointment at Cambridge University. Soon, however, Cattell went back to Leipzig, where he worked at Wundt’s center for psychological research. He continued learning about psychology from Wundt. There, the two of them conducted further research and had joint publications. During this time, Cattell gained knowledge in psychology and psychometrics, as well as valuable clinical experience. After a year as Wundt’s assistant, Cattell returned to the United States, first working at the University of Pennsylvania and then moving to Columbia University, where his influence as a psychologist really took off. At Columbia, he founded the Department of Psychology, the first at an American university.
In 1890, he published an important paper entitled “Mental Tests and Measurements,” in which he used the term “mental test,” probably for the first time (Cattell 1890, Cattell and Poffenberger 1947). In the paper, he both developed a theory of intelligence and proposed a mental test for it that was intended for use with the general population. His theory of intelligence comprises two parts: (1) agile intellect and (2) crystallized intelligence. These parts encompass as many as 100 abilities. He postulated that while everyone has all the abilities, they exist in different amounts and combinations for each person. Thus, everyone has a unique intelligence. Cattell thus set one of the first theories of intelligence.
Following in the tradition of Galton, Cattell’s tests of intelligence were a set of mental and sensory tasks, such as squeezing a hand, or the time needed for moving one’s hand 50 centimeters or judging ten seconds of time. The combination of tasks of both types (i.e., sensory and judgment questions) illustrates the development of mental testing, moving beyond the purely sensory tasks of Galton but not yet reaching the full intelligence tasks of Binet.
This is an important touchstone on the road to modern intelligence testing. In one important first, the Cattell tasks are intended for the general population and not for a given subset, such as persons with abnormalities. Significantly, Cattell was one of the first psychologists to apply psychometric methods to test development and to make a meaningful score and scale for them.
It seems Cattell was not only an imaginative academic but also a person of strong political opinions. He was opposed to not only the United States’ soon-to-be entry into WWI but to Great Britain’s involvement, and to the fighting in Europe as a whole. He expressed his opposition vociferously and often, to colleagues, students, and, seemingly, anyone else who would listen. When he was called to duty in the military, he refused. His refusal was not based on religious beliefs (for which he would have likely been excused) but on the more general political notion that no war is justified.
Administrators at Columbia University felt Cattell had gone beyond his scope of employ, and he was dismissed. However, Cattell fought back and sued the university, claiming it was unfair to dismiss him solely due to his political opinions. After an extended trial period, he won his case in court and was awarded a substantial sum for damages. The case became important in eventually establishing tenure as a job protection, thereby protecting teachers at all levels from being dismissed merely for having contrary political opinions.
With the awarded money, Cattell and two others founded a company to develop educational and psychological testing. They called it The Psychological Corporation. The company still exists today and sells standardized tests to schools, some institutions, and to licensed psychologists. It is worth noting that such tests (from this company and most others) are not sold to the public at large for a number of obvious reasons, including security, the training required to administer them, and the knowledge needed to properly interpret the results.
* * * * * *
Alfred Binet was another individual who promoted the idea that extra educational attention should be targeted to low achievers, although he worked much earlier than Jensen, and, of course, he was in France. Binet was a French psychologist who invented the first practical IQ test, the “Binet–Simon Scale.” (Théodore Simon was a student of Binet.) In 1904, the French government was interested in codifying its education laws and wished to bring resources to children who were slow in their school progress. But the French ministry of education did not know a reliable way to measure cognitive abilities uniformly across the country. A governmental commission was formed to study how this might be done, and, in 1904, Binet was asked to become involved by devising a suitable test.
Binet was a well-known scholar in France, particularly for his early work in abnormal psychology. He studied physiology at the Sorbonne campus in Paris, where he developed in interest in mental infirmities. Upon graduation, he accepted a position at Salpêtrière Hospital, a neurological clinic in Paris. There he studied hysterical paralysis, and, following the teachings of his mentor, Jean-Martin Charcot, he began using magnetism (by reversing polarity) to treat patients. For Binet, however, the results from these magnetism experiments were not positive, since he was not actually helping those in his care. He was forced to admit that he was not and that he had made a mistake by following Charcot. It was a setback for his career, but, with his new charge to develop a mental test, he had a chance to regain his reputation.
About the same time, Sigmund Freud also studied hysteria under Charcot, and that experience is credited with influencing Freud to pursue psychoanalysis, which he did independently.
In 1905, Binet designed thirty tasks in pursuit of this aim, thereby developing the first formal intelligence test useful for assessing children. In a departure from the early sensory-based activities of Galton and Cattell (e.g., hearing, depth perception), his tasks were entirely focused on higher mental skills. As illustration, a few of these tasks are listed in Table 16.2.
Table 16.2 A selection of tasks from Binet’s 1905 test (out of thirty in the original)
|
Task No. |
Task |
|
1 |
Follow a moving object with the eyes |
|
2 |
Grasp a small object which is touched |
|
4 |
Recognize the difference between a square of chocolate and a square of wood |
|
8 |
Point to objects represented in pictures (e.g., “Put your finger on the window”) |
|
10 |
Compare two lines of markedly unequal length |
|
15 |
Repeat a sentence of fifteen words |
|
16 |
Tell how two common objects are different (e.g., “paper and cardboard”) |
|
21 |
Compare two lines of slightly unequal length |
|
24 |
Produce rhymes (e.g., “What rhymes with ‘school’?”) |
|
28 |
Reverse the hands of a clock |
|
30 |
Define abstract words by designating the difference (e.g., “boredom and weariness”) |
He began his trial testing by first administering the tasks to his own two daughters! But once he had administered them, Binet realized that there was no prior scale for scoring his tasks—so he developed the first. Subsequently, Binet, now working with Simon, continued to develop his test. In 1908, Binet and Simon published an expanded test that had fifty-eight items and, in a significant change, introduced the notion of mental levels. In 1911, they published yet another revision that had tests for various age ranges, some of which extended clear into adulthood. These Binet–Simon scales constituted the first intelligence test, although the term IQ had not yet been introduced. Figure 16.3 shows the levels of his scale—they have been updated many times since his original invention.
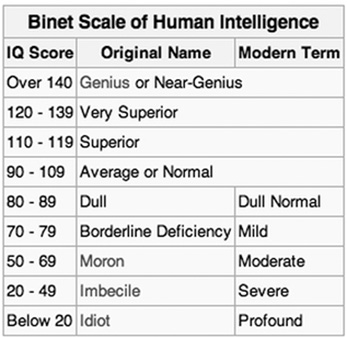
Figure 16.3 Binet’s early intelligence scale with levels
(Source: Public domain at http://www.freerepublic.com/focus/fbloggers/3267659/replies?c=1&q=1&page=37)
Then, Lewis Terman, a psychologist working at Stanford University in California in the early years of the twentieth century, revised the Binet–Simon scales into the Stanford–Binet intelligence test. Over the years, it has undergone a number of revisions and is still in popular use today.
Initially, Terman broadened the use of the test and began to explore its utility for examining giftedness in schoolchildren. He began a longitudinal study of characteristics of very bright schoolchildren: the “Genetic Studies of Genius.” Working in California public schools, he identified about 1,400 such children and began to track them throughout their lives. The study continues to today; about two hundred of the subjects survive. There are plans to continue following them for the remainder of their lives but not to add new subjects. The study has been criticized for a variety of technical deficiencies, but it remains the largest and longest-running study of intelligence and ability testing ever conducted.
Terman was a central figure in another IQ testing experience, now commonly referred to as the Army Alpha and Beta tests. During WWI, he was asked to administer an intelligence test to Army recruits, with the intention that the information would help identify those who could be trained as officers. The test was administered to more than 1.7 million recruits, making it the first large-scale IQ testing ever done. The test was in two forms: Alpha, which required examinees to read a series of questions, and Beta, which had only pictures and could be administered to those with low reading proficiency or nonreaders. The nature of the assessment demonstrated that IQ testing could be used broadly with a large population.
From this, IQ testing took off in schools, where it was widely employed for the next fifty years. Today, IQ tests are seldom administered across the board to a large group; instead, they are given individually, to one person at a time, and typically after some preliminary evaluation of an individual. Even with these attentions, many thousands of such tests are administered to schoolchildren and adults every year.
While there are several other persons important to the history of mental assessment, I will mention but one more: L. L. Thurstone. The son of Swedish immigrants, Thurstone showed a high intellect at a very early age. He studied engineering at Cornell University, but, after graduating, he developed an interest in the neurosciences. He developed a theoretical underpinning for making choices, whether you are selecting among alternatives on an IQ test or in daily activities. He called it the “law of comparative judgment,” and he derived a neurological rationale for it in psychophysics (Thurstone 1927). This work provides a theoretical foundation for modern methods of scoring a test.
In a related advance, Thurstone (working with Charles Spearman) developed a statistical methodology for finding overlap among a set of variables. The overlapping construct is termed a “factor,” and the procedure is called “factor analysis” (see Thurstone 1932). As many readers will recognize, factor analysis is commonly employed in psychometric analyses as well as in many areas of psychological research.
* * * * * *
Thurstone was interested in developing scales for tests and exploring new ways of scoring them. Rather than looking at just the number of test questions an examinee answered correctly, he posited that the pattern of responses might yield a more accurate score. Many diverse paths for analyses arise from this perspective, and I will mention one of them (the most popular today) momentarily. He developed his ideas in a classic work entitled A Method of Scaling Psychological and Educational Tests (Thurstone 1925). This work is more than simply classic research: Thurstone’s ideas have really taken hold in the past half-century, and they are growing in influence in modern testing.
Only a few years later, a Danish mathematician and Fisher protégé named Georg Rasch developed a statistical modeling approach that came to be called the “Rasch item response model.” This scaling model focused exclusively on the pattern of an examinee’s responses to a set of test questions. Rasch’s approach has attracted a group of ardent devotees. By the efforts of many others, the item-pattern response idea has evolved into a more general approach called “item response theory,” generally referred to as IRT. Because Rasch worked in the 1960s—a time later than our storyline—I will not elaborate on his other accomplishments. In truth, IRT was not original to Rasch, although he is credited with developing it into a testing model. (As with nearly all other mathematical developments, it has important antecedents, but they do not concern us here.)
Nonetheless, in modern educational and psychological testing, IRT is one of the more important psychometric developments of the previous century, and, therefore, I will describe it briefly. Also, note that, worldwide, most large-scale tests today employ IRT scoring. Some examples include NAEP, TIMSS, college admission tests such as the SAT and ACT assessments, and college general education tests such as College Basic Subjects Examination (CBASE). Many second-level school tests are also scaled with IRT.
To describe IRT (again, this is the briefest of explanations and omits many important details), it is first necessary to understand a bit about test theory. Most educational and psychological tests are classed as following “classical test theory,” also sometimes called “true-score theory.” In this concept, there is an exactly accurate test score for each examinee, called the “true score.” But realize, however, that a true score is only a theoretical possibility, because it is based on the assumption that there is no error in the testing (full validity and reliability). Errors in testing may emanate from many sources, including (1) an imperfect test instrument (e.g., imprecise wording of questions), (2) testing conditions (e.g., distractions during a test administration), or (3) the examinee (e.g., not fully engaged or inattentive during the test’s administration). All of these real-world circumstances lead to error.
We have seen error many times through the history of probability theory and the developing quantification mindset, such as when Galileo noted variations in his observations, or with the “true outcome” in Bernoulli’s law of large numbers. In all cases, these true scores or true outcomes exist only when the measurement is without any error from any source. By a simple formula, the true score is the observed score (here, termed X) minus any error, as seen in this simple formula:
![]()
In this assessment model, test questions (also called “items,” given that not all of them are interrogatives) are typically scored as right or wrong, meaning that every item is scored equally as 1 point. These points sum to the total test score. The error is estimated for the test by a reliability index.
IRT, however, envisions a wholly different perspective on the assessment process. In IRT, the focus is not on capturing the true score (despite the sources of error just mentioned) but on determining an examinee’s locale for a “latent trait” on a scale that (theoretically) extends from no ability in the trait to its complete mastery, expressed as minus to plus infinity. For example, for the latent trait of reading ability, the scale would stretch from wholly illiterate on the low end to a degree of complete mastery of reading on the high end. Now, the score is not the total of correct responses by an examinee but is shown in the pattern of responses. For instance, if any examinee responds inconsistently on a test by correctly answering some difficult items but missing easier ones, the score is less than if a consistent pattern of response is observed.
This idea can be seen in Figure 16.4, which is the trace line for a single test item. Note the horizontal and vertical axes. The horizontal axis (Trait level (θ)) shows the trait (say, reading comprehension) ranging from very low at the left to very high on the right. The vertical axis (P(θ)) is the probability (likelihood) of the examinee getting the item correct; it ranges from 0 to 1, as in 0 to 100 percent probability. As shown in the item trace line (its technical form is an ogive—recall we saw earlier that Galton originated this idea and invented the term), the higher the trait level, the more probable it is the examinee will respond correctly. Note that, for very able examinees (high on the trait level), the ogive comes close to 1.0 (a perfect probability), but it never actually reaches it, since, theoretically, no one ever has a 100 percent chance of getting the item correct.
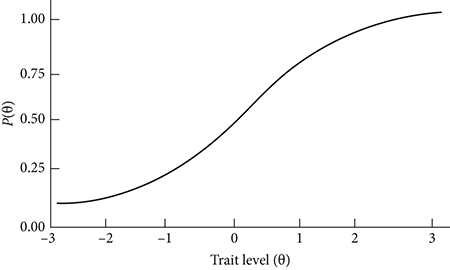
Figure 16.4 Item characteristic curve representing the relationship between an examinee’s ability and the probability of a correct response
Also, this illustration makes the name—item response theory—readily apparent. The formula for IRT is illustrated here, just so you can see what it looks like. However, when solved, the formula shows the probability of responding correctly to a test item, with the probability being dependent upon an examinee’s ability. To many psychometricians, it is all in a day’s work:
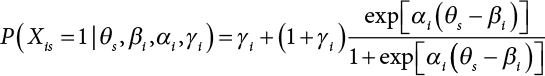
Psychometrics, as manifest in the science of educational and psychological testing, brings quantification to a truly personal level.