CHAPTER 6
On a clear, hot Sunday morning, July 8, 1741, in Enid, Connecticut, you sit in a wooden church pew listening to a thirty-something pastor deliver the sermon. Although normally shy and taciturn, the reverend is delivering his sermon in a loud voice, with special passion. You’ve long known some facts about your pastor: that he is a genius, a child prodigy who was admitted to Yale when he was only twelve years old; that he is highly regarded by the colonial leaders of early America; that he writes prodigiously about theology; and that he some years earlier married the stunningly beautiful Sarah Pierpont of New Haven, Connecticut, who bore him eleven children.
You know, too, other, important things about Sarah: that she is deeply pious, but unlike her husband she is gregarious and a remarkable conversationalist, which she uses to effect in convincing others to piety. In particular, you appreciate that she is hugely influential in shaping her husband’s thoughts and writings. It is obvious to those who know the couple personally that the young pastor (who could be “difficult”) is destined for greatness, in part owing to Sarah’s influence on him and the actions she takes on his behalf, such as making political contacts.
Earlier that morning, before traveling to the church, you completed your routine chores of milking three cows, setting hay out for your four horses, and moving some wood inside, closer to the fireplace. Your children have done their chores, too, feeding the chickens and the like. In the pastor’s home, Sarah prepared a warm breakfast and attended to the brood, getting them ready for church.
The reverend speaks his sermon with the intention that the parishioners not only hear his words, but feel them. He says:
The God that holds you over the pit of hell, much as one holds a spider or some loathsome insect over the fire, abhors you, and is dreadfully provoked. His wrath towards you burns like fire; he looks upon you as worthy of nothing else but to be cast into the fire. He is of purer eyes than to bear you in his sight; you are ten thousand times as abominable in his eyes as the most hateful, venomous serpent is in ours.
O sinner! consider the fearful danger you are in! It is a great furnace of wrath, a wide and bottomless pit, full of the fire of wrath that you are held over in the hand of that God whose wrath is provoked and incensed as much against you as against many of the damned in hell. You hang by a slender thread, with the flames of Divine wrath flashing about it, and ready every moment to singe it and burn it asunder. (Edwards 1741)
That morning, in that small church, the Reverend Jonathan Edwards delivered his famous sermon, “Sinners in the Hands of an Angry God.” Not surprisingly, the sermon made “remarkable impressions on many of the hearers” (1741). Soon, it came to rock people far beyond just the parishioners, spreading to believers across the new American colonies. Doubtless, the sermon was influenced by Sarah, who went on to help spread its message of “Reformed Theology,” holding that each human is a flawed soul with a natural predilection to wickedness and is only spared the fires of hell by a gracious God. This thinking was adopted by many early Americans as it moved quickly throughout the colonies. The Reformed Theology outlook was an emerging philosophy for the “Great Awakening,” a Puritan viewpoint that rejected the Enlightenment ideas of the Continent and set God at the center of all things. Its impact on thinking by American colonists was profound and lasting.
We know already that the work of Newton and John Locke had significantly changed humankind’s view of an individual’s relationship to God, proposing that people could employ their own free will to reason such a relationship and choose between good and evil. This view predominated in western Europe, as we saw in the Enlightenment epoch. But, in America, many colonists moved away from the ideas of the Enlightenment, not as a return to high church orthodoxy but to the puritanical view of Jonathan Edwards. Thus, there were conflicting viewpoints: Enlightenment on the Continent, and Puritanism (that so-called Great Awakening) in the American colonies.
This conflict of philosophies had an impact beyond religious debate: it also influenced the strides of humankind toward quantification. As a consequence of the different views, the developments toward quantification took divergent paths. I believe evidence exists to suggest that while advances in mathematics and measuring uncertainty continued briskly in Western Europe and Great Britain, Edwards’s “Sinners in the Hands of an Angry God” sermon stifled parallel developments in early America and slowed the progression toward quantification there. Hence, as humankind was moving forward in its viewpoint on one continent, this transformation was muted on another. There was plenty of brain power among the colonists. Remember, the great universities of Harvard, Yale, and William and Mary were already in existence.
But, significantly, the social and cultural context for mathematical and probability advancements that were giving impetus to quantification did not come to America until much later, whereas these forces were already strongly gaining ground on the Continent. We see, then, that quantification as a worldwide viewpoint did not grow everywhere uniformly.
With quantification, people are challenged to think differently: more expansively in both time and space, and more boldly in terms of impact. We move now on to the next step for when and how this happened.
* * * * * *
Meanwhile, prodigious advancements across Europe and Great Britain continued. Sometime during the 1740s—perhaps even the same year that Jonathan Edwards delivered his “Sinners” sermon—another clergyman, the Reverend Thomas Bayes, working in Great Britain, invented a simple but profound mathematical means to connect outcomes with causes. His proposition for study went something like this: is it possible to define how Event B is caused by Event A, knowing that the two things are related in some way?
This sounds like a simple and unremarkable achievement, but it turns out to be anything but simple—or unremarkable. It reaches to elemental truths, both in mathematics and in metaphysics. Bayes’s work was actually twofold: a mathematical challenge requiring a numerical theorem with attendant calculus proof, and a metaphysical conceit of ontology about the very nature of existence.
From these dual points of view, Bayes’s question can be stated more clearly, in a way that relates not just to a mathematical proposition but to how we process information to make decisions and reach conclusions. Now, his question is as follows:
When I learn new information about something that I already believe, how likely is it to make me change my mind?
I invite you to reread this question carefully and spend a moment pondering it, as it will occupy us for the rest of this chapter and beyond. As we will see, Bayes’s question is one of the most profound of all time. Fundamentally, it presents humankind with a true challenge—one that has directed people’s thoughts throughout history: how and why we change our minds. More specifically, how does one alter one’s beliefs in the face of new evidence? Being aware of Bayes’s challenge provides an entirely new perspective on thinking. It is that deep. It is indeed quantification in our daily thought processes.
Momentarily, we will see that his question has application across all sorts of circumstances in daily life, but first let us understand the true essence of that quintessential question. In examining it, I will introduce some terms that are useful to understanding it; these terms are commonly employed in discussion of Bayesian thinking. Note especially that Bayes’s question involves two pieces of information: “new information” and “something that I already believe.” Also, pay attention to the fact that there is an order to the information:
•the first consideration is “something that I already believe”: this is called a prior belief or simply a prior and in logic is typically represented as Event A;
•the second consideration is “new information”: this is called a new evidence or just evidence and in logic is typically represented as Event B.
An important aspect of these two elements is their relative strength. In other words, if one’s prior belief is strongly held, the new evidence must itself be powerful in order to be motivating enough to change one’s mind. Conversely, if one’s prior belief is only weakly held, the new evidence need be only weak itself to be motivating enough for a change of mind. Imagine for each statement that there is sliding scale of confidence or adherence, with weak on the left side and strong on the right side. Reread the two bullet points but this time with consideration of their sliding confidence scales. Imagine how when one scale slides up, the other slides back, causing you to either hold fast to your prior belief despite new evidence or change your prior because of the new evidence.
With our new terminology in place and with this elaborating information, here is Bayes’s question stated again:
When presented with new evidence about a prior belief, what is the probability that I will change my mind?
Addressing this question methodologically is called “Bayesian thinking” or “Bayesian estimation.” The latter term suggests it is a problem in probability theory, and this is exactly how Bayes addressed it. Now you can appreciate how foundational Bayes’s proposition is. We do this kind of thinking all day long, instantaneously. But specifying it mathematically is quite another thing—this is what Bayes has done. It is truly a remarkable feat, and one with profound implication for our daily lives.
An additional important point is to realize how hugely innovative and imaginative Bayesian thinking is. Before Bayes brought his idea to the table, probability was a concern of counting the frequency of events. This was done by sampling a population, carefully and deliberately, as we saw in Chapter 5. By the central limit theorem, persons working the field knew the true mean of a population is ever more accurately estimated as the number of samples (or trials in an experiment) increases.
But, in a practical sense, only so many samples may be drawn; hence, the true mean is only theoretically derived and never actually known. Even when there is a high degree of accuracy in its estimation, the true mean is just a highly informed guess. There is no consideration of confidence in the value taken as the true mean; rather, by this thinking, the mean is simply accepted as true or not. Other statistics (e.g., the standard deviation) are calculated from this accepted value.
Such an approach to data is called “frequentist” because it stems from the frequency of counting samples. Frequentist thinking dominated probability theory—and was predominant among mathematicians and other probability theorists—since the beginning and continues a strong tradition today. Sometimes statisticians refer to themselves as “frequentists,” meaning that they adopt this perspective for data handling.
But, as we saw in Chapter 5 (with Bernoulli’s law of large numbers and Laplace’s distributions of linear combinations of large numbers of independent random variables into the central limit theorem), there is another way to view the true mean of a population. This alternative—called (surprise, surprise) “Bayesian”—views the true mean not as a given value to be estimated but as itself a value that falls within certain limits. With Bayesian estimation, that probability can—indeed, should—be determined.
To see the difference between frequentist and Bayesian thinking, consider a simple example. Suppose, after many samples (everything very carefully done), a mean value of 70 is calculated. The frequentist would accept 70, be done with further refinement of the true value, and proceed to calculate other statistics and follow-on procedures. They could then happily go to lunch.
The Bayesian, however, is just getting started. This person sees the worth of modeling 70 as a probability of falling within certain limits, say, between 68.5 and 71.5, as in this expression: P(68.5 < 70.0 < 71.5) = 95%. This expression means that, given that the true value actually falls with the range from 68.5 to 71.5, there is a 95 percent probability that the observed value 70.0 falls within the range of the actual true value. We return to this point in Chapter 9, where its larger context is given.
Here, Bayes presents this idea as logical thinking in probability theory. Later on, we see that Gauss defined it mathematically as a probability density function.
From this brief introduction, we now turn to learning a bit more about Bayes and then to how he solved his estimation problem—this “Bayesian estimation.” We’ll learn quite a bit, too, about how it fits into our mindset today. Think quantification. You may be surprised!
* * * * * *
To truly understand Bayes’s reasoning, it is necessary to appreciate the social and cultural context in which he was working, a point emphasized throughout this book. Bayes, remember, was a Presbyterian minister, every bit as devoted to preaching and practicing his faith as was Reverend Jonathan Edwards in America delivering his Reformed Theology in his “Sinners in the Hands of an Angry God” sermon. Thus, Bayes saw probability theorizing as religious: a study in theology put into practice via mathematics. Bayes sought to prove the existence of God. Bayes was working from a point of view called the “God argument,” wherein all things in creation are original to the Creator, including mathematical theorems and all other numeracy. Humankind has only to discover them, which is itself a glorification of God.
This was the same intent proposed by de Moivre for his work that we saw in Chapter 5. Bayes had an additional advantage over his most of his minister colleagues because he was a gifted mathematician, and he knew he could employ his specialized calculus skills in his religious pursuit, too.
The thinking of Bayes and de Moivre (and many others from this era) brings to the fore a subtle but important ramification of the God argument in mathematical reporting. Some authors of the histories and chronicles of mathematics, when mentioning a new equation or math, use the term “invented,” whereas others describe things with the word “discovered.” At first blush, this may seem like an inconsequential difference in terminology, but it turns out there is a lot of substance to the choice of wording. It is revealing of differing perspectives. In one, everything—for example, mathematical advances, prior beliefs, and the orbits of celestial bodies—is “discovered” because it comes from God. (Recall that Newton, by introducing gravity as an explanation for physical phenomena, upset this belief.) In the other, these things are “invented” as original thoughts and ideas, stemming from an individual. For the Reverend Bayes, we clearly know his point of view.
Bayes laid out his mathematical invention in his magnum opus An Essay Toward Solving a Problem in the Doctrine of Chances (Bayes and Price 1963). From the title, one may imagine that Bayes intended to make only a slight comment and perhaps suggest some minor development to de Moivre’s work, but his essay turns out to be much more than just a few remarks. It lays out probabilities and the whole perspective of Bayesian thinking, sprinkled liberally with religious references.
Bayes’s first efforts in probabilistic thinking were to advance the three theorems of numbers we saw earlier: the binomial, the law of large numbers, and the central limit theorem. He worked specifically on solving the missing calculus of de Moivre’s Doctrine of Chances. But as time went on, his work went much further than simply advancing the theorems. Because he was working from the God-argument perspective, he was very open in his thinking, always looking for new “discoveries” as ways to glorify God. Rather than limit his work to just numbers and equations, this broader perspective took him on a journey into the then-nascent field of probability theory.
His quest led him to explore why things happened, beyond the how of mathematics. When carried out, his efforts proved so elemental to the theory of probability that, almost inadvertently, he formulated it as a whole discipline. Although not the first to focus intellectual efforts on studying probability itself (we have already seen several folks interested in the pursuit), Bayes did bring to the field a structure and direction. Until that time, it had been considered a subordinate branch of statistics, and its developments were not organized under a cohesive rubric. Now, probability theory was itself an independent study.
Now, I draw these things together. Imaginably, Bayes’s most notable single accomplishment—the one that gave form to the whole of probability theory—was to invent “Bayes’s theorem” (also called “Bayes’s rule” or “Bayes’s law”). This is the Bayesian thinking (also Bayesian estimation) we just saw in his famous question. At essence, Bayes’s theorem defines the rules for probabilistic thinking. So important is Bayes’s theorem in establishing probability theory that it has been said that it “is to the theory of probability what the Pythagorean theorem is to geometry” (Jeffreys 1973, 31).
In intellectual circles from many disciplines, Bayesian thinking is widely—and deliberately—accepted. It is a near-perfect thought in science: “When presented with new evidence about a prior belief, what is the probability that I will change my mind?”
Even apart from academia, Bayesian thinking is adopted widely. In economics, as just one example, there are many Bayesians. Microsoft cofounder Bill Gates, early in Microsoft’s history, declared that he was a Bayesian in his approach to many practical computer problems. It is not unheard of for college students to wear a T-shirt emblazoned with “I am Bayesian” (definitely something for the cryptic in-crowd). It is adopted in many other contexts, too. In fact, you may use it in your thinking—with your fully quantified worldview—without even realizing that you are Bayesian, too!
Bayes did a lot of his developmental work while tutoring students in local pubs. He was a respected teacher. Taking advantage of his immediate resources (in his circumstance, a billiard table), he taught his theorem to many. Figure 6.1 is a graphic made by Bayes himself to illustrate his problem. If the figure immediately brings to mind the three theorems discussed earlier—the binomial, the law of large numbers, and the central limit theorem—you are indeed observant. Bayes’s theorem is built on them.
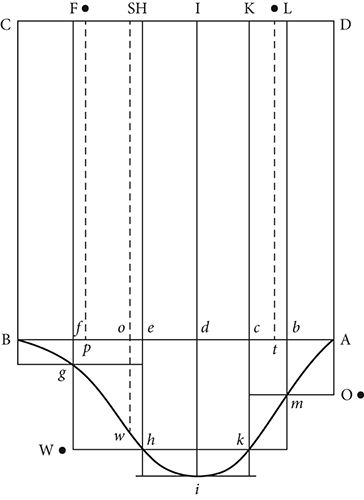
Figure 6.1 Bayes’ illustration of estimating probability using a billiard table
(Source: from T. Bayes, An Essay Toward Solving a Problem in the Doctrine of Chances)
To illustrate his argument, Bayes had two billiard balls, which he labeled W and O. Before rolling the balls, he hypothesized that they would stop somewhere between the shortest roll (the horizontal line B to A) and the longest roll (a distance of the vertical line I to i). He made this his scale of 0 to 1. He rolled the W ball down the table and measured the distance to where it came to rest. He hypothesized that 50 percent of subsequent rolls would stop to the left of his original toss. This hypothesis was his prior belief; that is, a belief before new evidence is presented. He then rolled the W ball many, many times, each time recording where it stopped. He used this scenario as a means to question his prior belief. With only a few rolls, he did not change his prior, but as more evidence was garnered, he slowly began to change his prior belief, eventually coming to a changed belief (say, that 60 percent of the time, a rolled billiard ball would come to rest to the left of his original roll).
Then he repeated the whole scenario with the O ball—but this time recorded when each ball rolled to the right of his initial O ball roll (testing again this new prior). His demonstration was of how a prior belief changes when presented with new information and that the change is proportional to the strength of the new evidence. Significantly, as anticipated, the distribution of the number of occurrences where the balls rolled (to the left or to the right) was a binomial, which we know from the famous three theorems eventuates into a bell-shaped distribution.
* * * * * *
Now, we can really get into the Bayesian mindset, where things get interesting (don’t worry—not more complicated, just more interesting!). Bayesian thinking is inductive reasoning, wherein a conclusion (which itself is usually a general statement or rule) is reached from prior observations. For example, suppose one is given a series of numbers, say 3, 6, 9, and 12, and is asked to determine the next number in the series. As seen, the prior observations are a numeric series incremented by 3. Hence, by inductive reasoning, one would conclude that the next term is 15 because it is the next increment of 3 (12 + 3 = 15). Inductive reasoning is opposed to deductive reasoning or abductive reasoning. Inductive reasoning is commonly employed in mathematics and used throughout all of scientific research.
The seventeenth-century philosopher and orator Sir Francis Bacon saw inductive reasoning as a way of understanding nature in an unbiased way, as it derives laws from unbiased observation. His thinking—done only about one hundred years ahead of Bayes’s productive years—was enormously influential in setting ground rules for the scientific method and the observational techniques we saw in Chapter 3 with Mayer and the others. Now, we will use inductive reasoning in Bayesian estimation.
As we realize by now, Bayesian thinking—estimating the probability of changing beliefs based on new evidence—involves contemplating a set of probabilities: (1) the probability of a prior belief being true and (2) the probability of new evidence causing a change in the prior. Taken together, these considerations coalesce to form a central feature of Bayesian estimation: “conditional probabilities.”
Conditional probability is the probability that Event B will occur given that Event A has already happened, and presuming (of course) that the events are related. Thus, conditional probabilities require three elements: Event A, Event B, and their intersection. Both events must be true and can occur independently, but they must relate in some way (i.e., have a correlational relationship, whether positive or negative).
Before going further on conditional probabilities, I pause to mention a closely related idea that is often confused with it: a “joint probability.” Without realizing the distinction, either type of probability can be misinterpreted. A joint probability is merely the likelihood that two events are true. It does not have the added stipulations for the conditional probability described in the previous paragraph. For example, consider the two live births, where one is a girl and the other a boy. There’s no dependency and no sequence—simply A and B. It brings the question, “What is the probability from two live births that one will be a boy and the other a girl?” This circumstance is a joint probability. The answer is 25 percent, because the sex probability for each birth is 50 percent (0.5), and 0.5 × 0.5 = 0.25. This is a legitimate joint probability question, but not a conditional probability.
Conditional probabilities commonly appear in our daily lives, even though few of us have previously classified our thoughts as such. Some examples of conditional probabilities are given in the following list. Each example of Bayesian thinking is from real life. In other words, they are nontrivial scenarios. As a feature of the theorem’s richness, these probabilities can be simple or complex. Note that the scenarios meet Bayesian conditions: each event is true and can occur independently of the other event, but there is some meaningful relationship between them, and they have a sequence of one first, then the second:
•A class is given two tests. Fifty-one percent of the students passed the first test, and 25 percent of them passed both tests. What percentage of those who passed the first test also passed the second test?
•A pharmaceutical company advertises that its test for a particular disease is 99 percent accurate. A negative test result indicates the patient is free from the disease. If 1 percent of the population has the disease and you test positive, what is the probability that you actually have the disease?
•A robotic machine welds circuit boards for televisions. Ninety percent of the boards are perfect, 2 percent of them can be easily repaired, and 8 percent of them are defective. An inspector discards the defective boards. What is the probability that the inspector will incorrectly pass a board that could be repaired or is defective?
•In the general population, 0.055 percent of males die before their fiftieth birthday. Also, about 0.011 percent of males younger than fifty have cancer, with a survival rate of five years. What is the probability that a forty-five-year-old male will celebrate his fiftieth birthday? With a cancer diagnosis? With a negative cancer diagnosis?
•A survey question asked, “Is there solid evidence that the earth is warming?” The results for a “no” response were 53 percent for Republicans, 14 percent for Democrats, and 31 percent for independents. According to earlier information, 33.1 percent of voters are Republican, 34.6 percent identify as Democrat, and 32.3 percent are independent. Given that a particular voter does not believe there is solid evidence that the earth is warming, what is the probability that the voter is Republican?
•The probabilities of having a boy or a girl are each 0.5. A couple has two children, the older of whom is a boy. What is the probability that the couple has two boys? (Note: there is an ordered sequence in this scenario.)
These conditional probabilities (and many millions of others), are solved with Bayes’s theorem.
The mathematics of calculating Bayesian probabilities is relatively simple, but setting up the problem requires that one understand the logic of Bayesian scenario. Here’s the rub, because it is where most folks get lost. Hence, I have spent much time explaining it, from various angles. The logic is not difficult, but it is not intuitive. It requires one to diagnose a scenario and arrange its parts into the Bayesian thinking. For a quick review, recall Bayes’s elemental question, which was discussed earlier in the chapter and is repeated here for convenience: When presented with new evidence about a prior belief, what is the probability that I will change my mind? Keep in mind, too, that idea of conditional probabilities. Finally, we reach a tangible point to move forward: that is, we can solve a conditional probability to give answer to Bayes’s question.
Bayes’s theorem is typically expressed using the set notation of logicians, as follows:
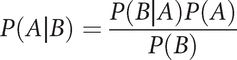
Here, the conditional probability of Event A given B is denoted by the term P(A|B), which is read as “the probability of Event A, given Event B,” as seen in the left side of the equation. Like all mathematics equations, the set notation of the theorem follows Euler’s order of operations, mentioned earlier. We have just seen the left side of the equation, so now move to the right side. It reads, “The probability of B given A, times the probability of A, divided by the probability of B.”
The outcome term P(A|B) is the final conditional probability solution. As it occurs after the problem itself, it is called the “posterior probability.” The term P(A) is the initial degree of belief in A (the probability of A), or the prior probability. The term P(A|B), as we have already seen, is the degree of belief after having accounted for B. And the term P(B|A) P(A) represents the support provided by B to A, or the influence of the evidence on changing the prior belief.
Sticking to just the logic (and eschewing the math, despite its being not at all difficult), suppose some adult American smokes cigarettes regularly at the rate of one pack per day and is interested in learning the odds of being diagnosed with cancer this year. We start the short journey to solution by looking at the incidence in the population of each phenomenon independently. First we ask, “How many adult Americans smoke at least one pack of cigarettes daily?” We then ask, “How many adult Americans received a first-time cancer diagnosis this past year?” Each amount is known from health surveys. Taken separately, these questions are simple frequency counts that are usually expressed as a percentage of the population, and the probability for each is the ratio between the number counted and the population.
According to recent disease statistics, the cancer incidence in adult Americans is 455 per 100,000 men and women (National Cancer Institute 2018). Hence, one has about a 5 in 1,000 chances (actually, 4.6 in 1,000) of having cancer diagnosed, or a probability of roughly 0.005 percent, from any cause. Similarly, for cigarettes, about 15,100 per 100,000 adults smoke (an interesting side note is that slightly more women than men smoke): about 15 of every 100, or a probability of roughly 15 percent. In this scenario, thus far, there is no dependency, and the circumstance is simple to describe.
When the conditions of the two probabilities—the incidence of cancer, and the incidence of smoking—are considered together, however, both logical and computational difficulties arise. The new, combined question we can surmise from what we have learned already is “Given an adult American who smokes at least one pack of cigarettes daily, what is the probability of that individual receiving a first-time cancer diagnosis?” This dependent consideration is a conditional probability. There are some mathematical stipulations for everything to work out. And we have already seen them: namely, the events must be independent (i.e., each can happen separately), and they must relate in some way. We have long known that cancer and smoking are related. Here, we wish to consider them together, or “conditionally.”
Our initial hypothesis for answering the question is just the odds of receiving a cancer diagnosis this year—which we know to be 0.005 percent, our prior information. We evaluate our prior against the evidence, that is, the known proportion of smokers in the population (approximately 15 percent). Bayes’s theorem makes a ratio of these two probabilities. This combined ratio is the conditional probability. In this scenario, the conditional probability calculates to approximately 3 percent chance of receiving a new cancer diagnosis this year, given the fact that the individual smokes one pack of cigarettes daily.
The following famous problem is often used when teaching Bayesian estimation: determining the chances of a woman having breast cancer. From Centers for Disease Control statistics, about 10 out of every 1,000 women aged 40 to 50 are diagnosed as having breast cancer (about 1 percent). But the initial screening test is not infallible. A woman with breast cancer has a 90 percent chance of a positive test from a mammogram, while a woman without cancer has a 10 percent chance of a false positive result. Hence, the question refines to “What is the probability of a woman actually having cancer given that she had a positive screening test?” This is Bayesian conditional probabilities in action.
Stated in Bayesian notation given earlier, this is
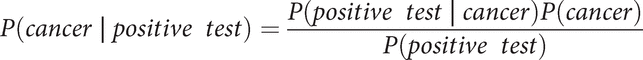
In other words, the left side of the equation is the question under consideration (remember, the line | means “given”). The right side of the equation is the probability of a positive test, given actual cancer, (0.90) times the probability of cancer at all (0.01), divided by the probability of a positive test, which is the four percentages of all possibilities. With numbers plugged into the equation, it is now
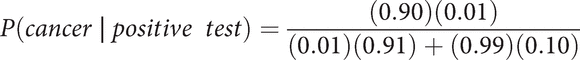
![]()
Thus, the probability of a woman actually having cancer, given that she had a positive screening test, is about 8.3 percent. Incidentally, when one hundred physicians were given these statistics and asked the question, more than three-quarters of them responded incorrectly. The good news is that fewer women actually had cancer than they anticipated. With Bayesian estimation, we know the probability more exactly.
From the foregoing, I now present a fun problem of Bayes’s theorem and Bayesian thinking. The problem I will give here is very simple, but appreciate that it is one that Bayes would find utterly incomprehensible, since it involves the twentieth-century ideas of a TV game show and cars, neither of which was invented until well more than a century after his death. Notwithstanding, this famous illustration of Bayesian thinking is called the “Monty Hall problem.”
Readers may recall the very popular TV game show from years past Let’s Make a Deal. During its most illustrious run (from about 1960 into the 1980s), a Canadian-American named Monty Hall was the host (although he has since passed away and the show now runs with new hosts and in worldwide syndication). In the show, a lucky contestant was brought onto the stage where Monty presented her with three closed doors, enthusiastically explaining that behind one of the doors was a fabulous prize (like a new car)—but behind the other two doors lay a dud prize (like a goat).
To a cheering audience, the contest would select one door, say Door no. 1, leaving Door no. 2 and Door no. 3 not selected. To prolong the suspense, Monty Hall—who secretly knew where the car was—did not immediately open the selected door (in this case, Door no. 1). Instead—and playing full on to the audience—he opened one of the unselected doors, always opening a door that revealed a goat. Say he opened Door no. 3. This left two doors still unopened: Door no. 1 (the contestant’s initial choice) and Door no. 2. Then, Monty asked the contestant if she would like to change her choice from Door no. 1 to Door no. 2. As you can imagine, the audience loudly chimed in with shouts of “Change!” or “No!”
This scenario is a perfect Bayesian conditional probability. At first, there are three unknown doors. Of course, the contestant wants the car and “hypothesizes” that it is behind Door no. 1 (just a guess among the three choices at this point, but still a hypothesis with a 33 percent chance for Door no. 1). But then Monty Hall opens either Door no. 2 or Door no. 3 to reveal what is behind it, which is equivalent to presenting new evidence. We know that he always opens a goat door. Then, the Bayesian question is asked of the contestant: “Do you want to change doors?”, or, in Bayesian terminology, “Modify your original hypothesis?”
Most contestants are unaware of conditional probabilities and approach the door choice as just simple odds: at first, there is a one-third (33 percent) probability of selecting the car door; and when Monty Hall takes one of the unselected doors out of consideration by showing a goat behind it, the contest thinks, “Ah-ha! With just two doors left, I now have a fifty–fifty chance, so it makes no difference whether I keep my original choice or change doors.” But the contestant is not employing Bayesian conditional probabilities. We know there is a better way to approach the door choice.
To see the problem as conditional probabilities, consider it from the beginning. At first, the hypothesis is just a one-third probability (33 percent) of choosing the car door, leaving a two-thirds probability (66 percent) of not selecting the car door. Stated as opposite, there is a two-thirds probability that one of the two unselected doors conceal the car. Now, think Bayesian: Monty Hall opens a goat door, leaving just one unselected door. But the two-thirds probability (66 percent) of those doors hiding the car has not changed. Hence, with the new evidence (one goat door known), we happily change our choice to the remaining unselected door. In doing so, we have doubled our odds. That is, by the change, the contestant has increased the probability of selecting the car door from 33 percent to 66 percent. Now you know that when confronted with this scenario, you should always change from your initial selection to the new choice.
A tree diagram of the problem, where the player initially selects Door no. 1, is shown in Figure 6.2.
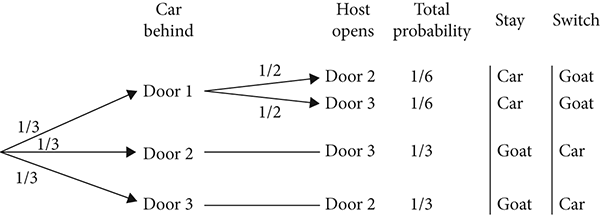
Figure 6.2 Tree diagram of the Monty Hall probability problem
A version of the Monty Hall problem uses one hundred doors, one of which hides a car while the other ninety-nine doors conceal goats. Here, the contestant initially selects any door, at random, for a 1 percent probability. From the remaining ninety-nine doors, Monty Hall then opens ninety-eight of them—all goat doors. Now, only two unopened doors remain. An unsuspecting contestant may think the odds have increased from 1 percent to 55 percent. But we know better: given the new evidence (ninety-eight goat doors removed from consideration), the odds change from 1 percent to 99 percent. Change doors—you’ll almost certainly get the car!
There is yet another surprising fact about the Reverend Thomas Bayes’s work on his theorem. After making his initial revolutionary invention, rather than continuing to advance his accomplishment, he abandoned working on it altogether. In fact, he did not labor on this problem for the remainder of his life. No one knows why he stopped working on his revolutionary approach to linking causes with evidence. Perhaps he did not appreciate his own accomplishment, although by his words and other achievements (wherein he applied the theorem and discussed his approach), this seems unlikely. Fortunately, it was rediscovered later by another mathematical genius, Pierre-Simon Laplace, who gave it its modern mathematical form and scientific application. Nonetheless, it all started here—with Bayes addressing the God argument.
When Bayes’s theorem initially came on the scene, the notion of contingent probabilities was called an “inverse probability.” The word “inverse” means a reverse in position: here, Event B is reversed, or reconsidered, based upon the outcome of Event A. Since conditional probabilities always calculate odds, it means that the likelihood of Event B is considered in light of the odds for Event A. Although some may consider the wording “inverse probability” awkward, it is rather descriptive. It captures the connection between causes and outcomes, expressed by a probability: the likelihood ratio.
It is almost impossible to overstate the influence of Bayes’s theorem. It has surprising relevance to our lives today. We see it everywhere. Many readers will recognize that Bayes’s theorem (at least the logic and solution part, often without calculations) is routinely taught in classrooms across the world, from high school to graduate school. Its ubiquity is amazing. It is used every day by people working in literally hundreds of occupations, from finance, to business, to medicine, to sports, to engineering, to law—almost everywhere. For example, many modern machine learning techniques rely on Bayes’s theorem. Spam filters use Bayesian updating to determine whether an email is real or spam, given the words in the email as evidence.
In addition, many specific techniques in statistics, such as calculating P values, are best described in terms of how they contribute to updating hypotheses using Bayes’s theorem. In 1992, Bill Gates announced that “Microsoft’s competitive advantage lay in its expertise in Bayesian networks” and that “Bayesian theory is firmly embedded in Microsoft’s Windows operating system” (quoted in McGrayne 2011, 242–3).
There is an entire specialty within criminal and civil law of probabilistic jury selection and legal defense. I recently came across an Internet site devoted to cataloging legal cases where evidence was based on Bayes’s theorem. It currently lists more than three hundred cases, many of which are important and well known, including the infamous O.J. Simpson murder case. The question was “What is the probability an individual with matched blood type, identical shoe print, and having sufficient strength, as well as with a known motive and opportunity, could have committed such horrific murders?” The judge did not allow this probability evidence because, he said, he did not understand it. Cases in which DNA evidence is used to either convict or exonerate a defendant also rely on probabilistic evidence calculated by Bayes’s theorem.
A nontechnical and delightfully readable historical account of Bayesian statistics is offered by Sharon Bertsch McGrayne, a journalist who assembled numerous anecdotes of important and unexpected uses of Bayesian statistics in a book titled (ready for a mouthful?) The Theory That Would Not Die: How Bayes’s Rule Cracked the Enigma Code, Hunted Down Russian Submarines, and Emerged Triumphant from Two Centuries of Controversy (2011). Evidently, she didn’t want you miss anything. Notwithstanding the book’s title, it does show the ubiquity of Bayes’s theorem in our lives today.
For us, Bayes’s theorem is a touchstone accomplishment to quantification.